Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Incremental Loading with Coalesce
Overview
Incremental data loading is a technique used in data warehousing to efficiently update large datasets by only processing and loading new or changed data since the last update, instead of reloading the entire dataset each time.
For example, you're an e-commerce company and only want to load order changes, not all orders every time. You can use the Incremental Node to only update records that have shipped.
Coalesce makes this process easy by offering the Incremental Node Package. By using our Package, you can quickly get started building your pipeline with minimal code and configuration. The package contains the following Node Types:
- Incremental Load - Performs updates by loading only new or changed records. It minimizes data duplication and optimizes resource use by focusing only on changes since the last load.
- Looped Load - Runs multiple loads in a loop, which allows the system to handle large datasets in smaller batches. Each loop processes a subset of data, reducing memory usage and improving performance for larger tables.
- Run View - Creates a view that tracks the most recent runs. The view is refreshed with each execution, allowing for easy identification of the latest updates or changes without reloading the entire dataset.
These Node Types make sure you can follow best practices such as:
- Change detection - Identifying new, modified, or deleted records in the source system since the last data load.
- Efficiency - Reducing processing time and resource usage by only handling changes instead of the full dataset.
- Timestamp or version tracking - Using timestamps or version numbers to determine which records have changed.
- Maintaining historical data - Preserving historical information while updating with new data.
You can learn more about Incremental Processing Strategies in our blog post.
Coalesce uses High Water Mark as a fast and efficient way to process data
Before You Begin
- If you don’t have a Coalesce account, you can start a free trial from our Snowflake Marketplace listing.
- This demo uses the Snowflake sample data sets.
- Set up your Storage Locations and Storage Mappings.
- Add your source data.
Install the Incremental Loading Package
You're going to install the Incremental Loading Package.
-
Choose a package from the Coalesce Marketplace.
-
Make note of the Package ID.
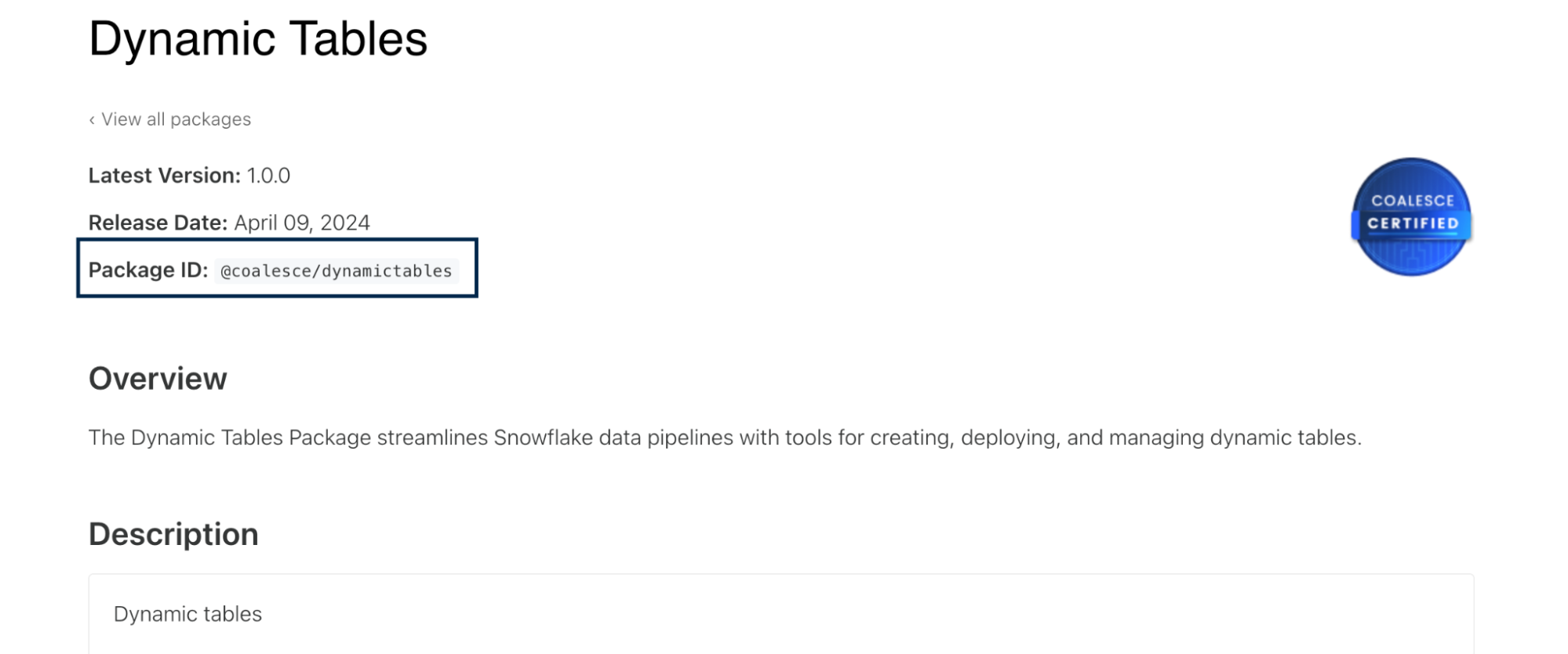
-
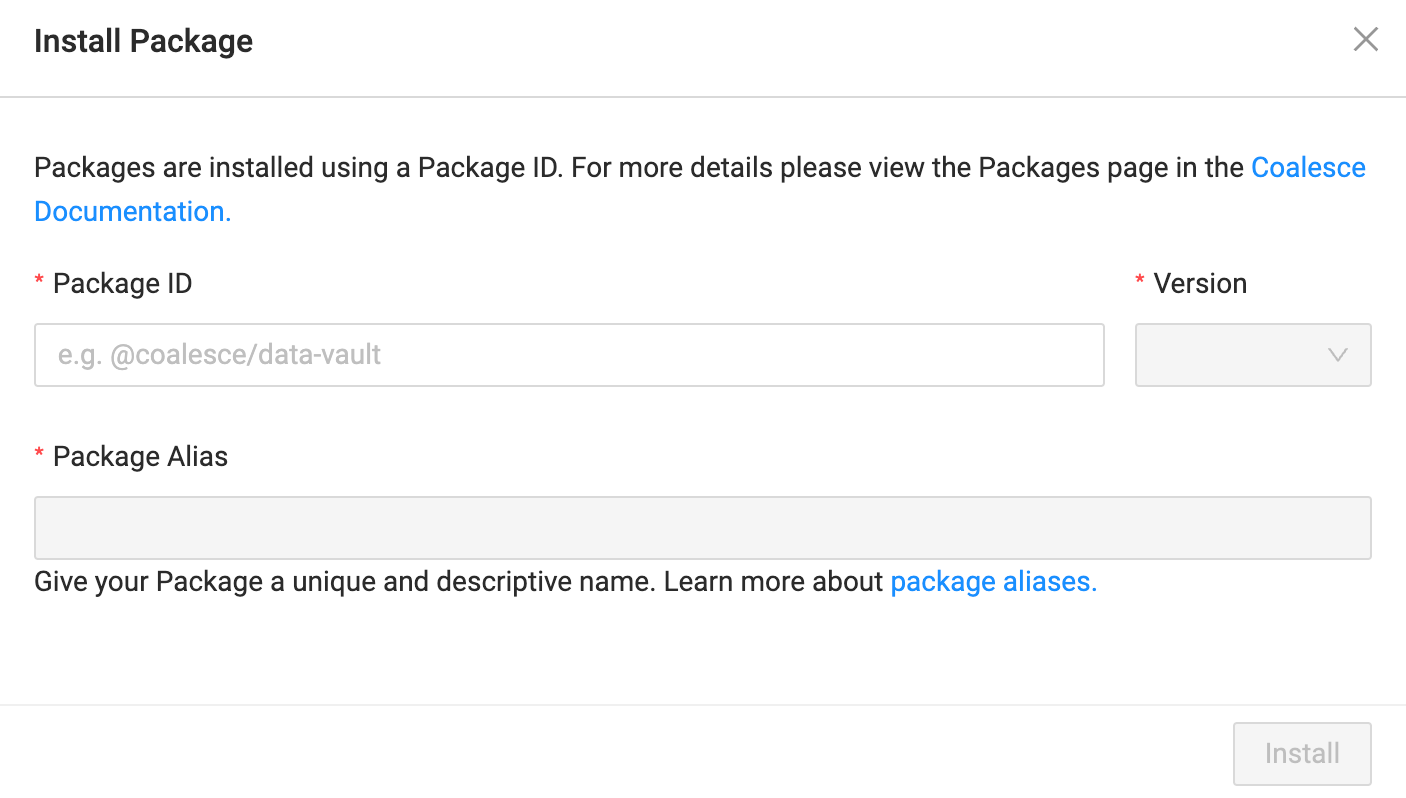
In the Coalesce App, go to Build Settings > Packages. Click Install.
-
Enter the Package ID you previously copied.
-
Select the version you want to install.
-
Enter a Package Alias. The alias is a unique and descriptive name for the package so you can easily identify it later.
- A package alias can only contain letters, numbers, and dashes. It can’t contain consecutive dashes.
- Package aliases can’t start or end with a dash.
-
Install your package.
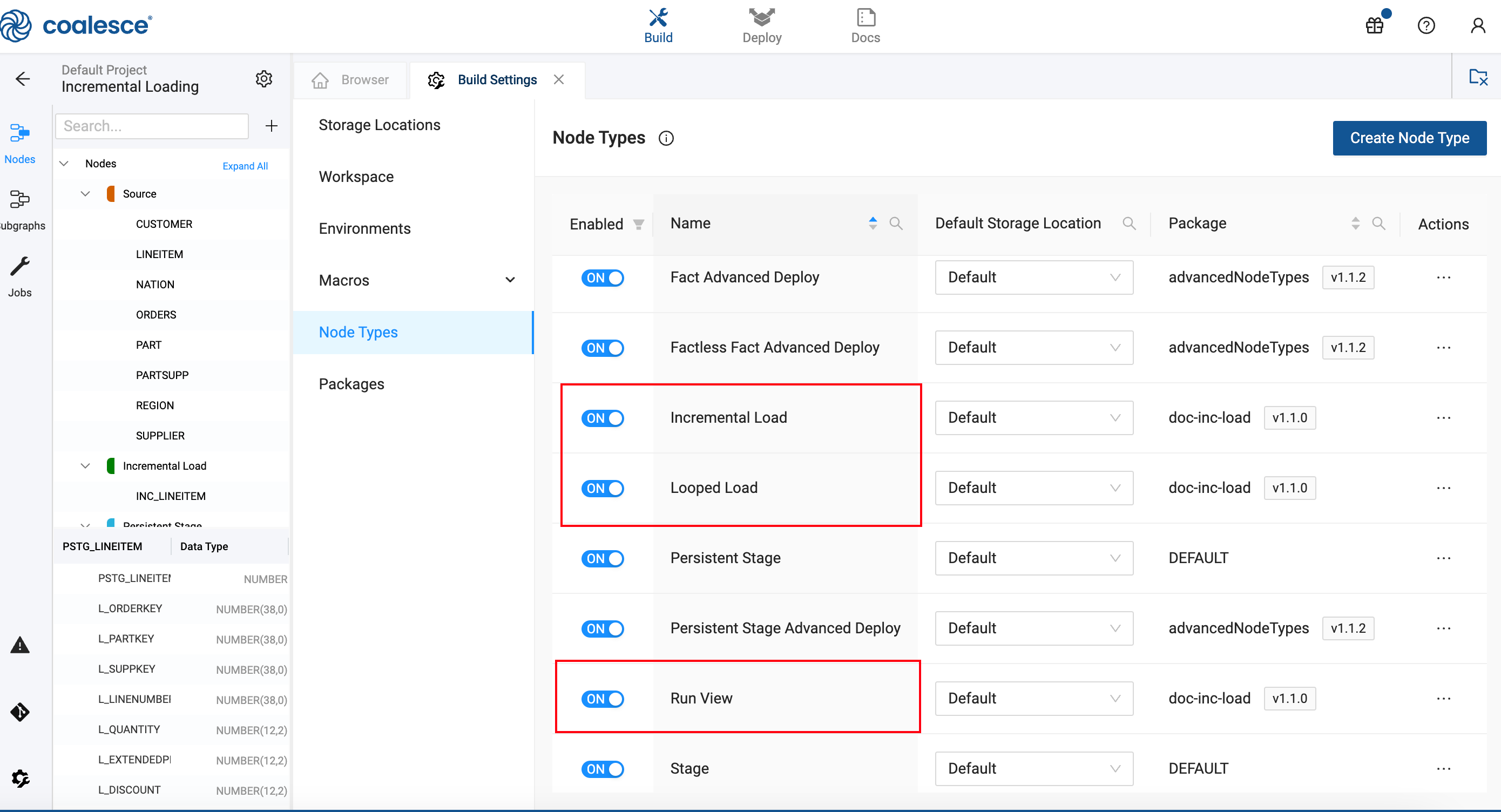
Click on Node Types to see the three Node Types included in the package:
- Incremental Load
- Loop Load
- Run View
Add Your Nodes
-
Right click on the
LINEITEMsource node and select Add Node > Select the Incremental Node Package.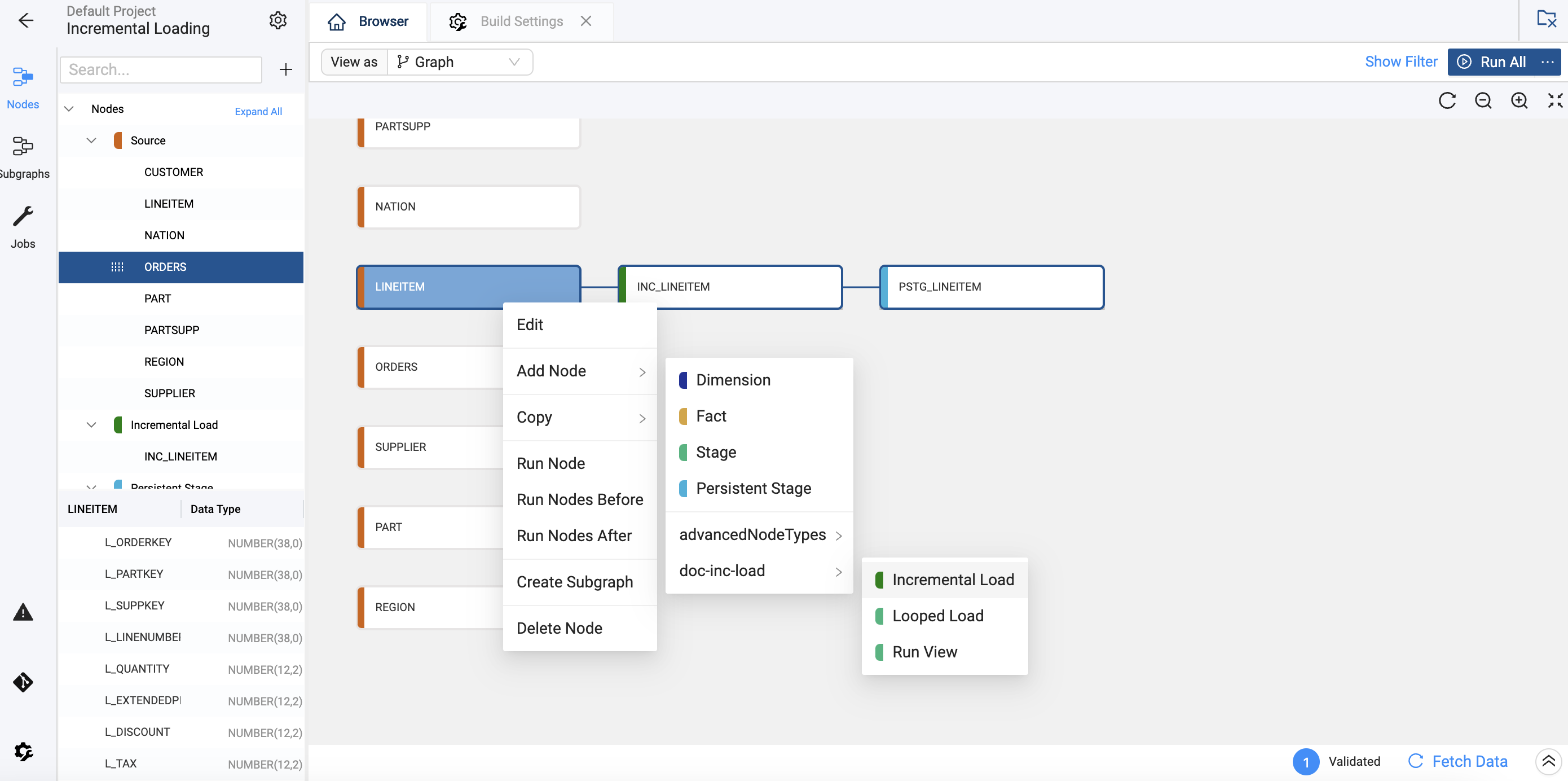
-
Open the Node Properties.
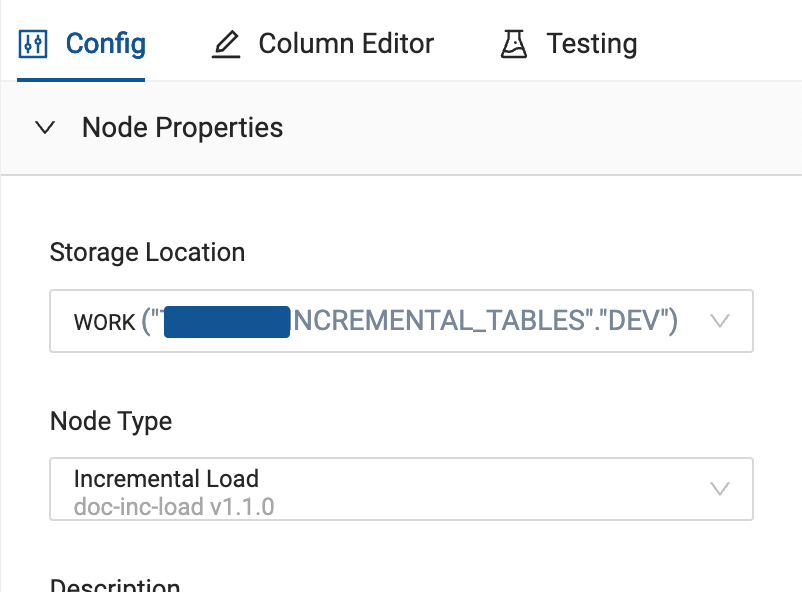
-
Take a look at the Storage Location. Make sure it’s not the same location as your source data.
 Best Practice
Best PracticeYou should create a separate Storage Location for your Incremental data when using this in a production environment.
-
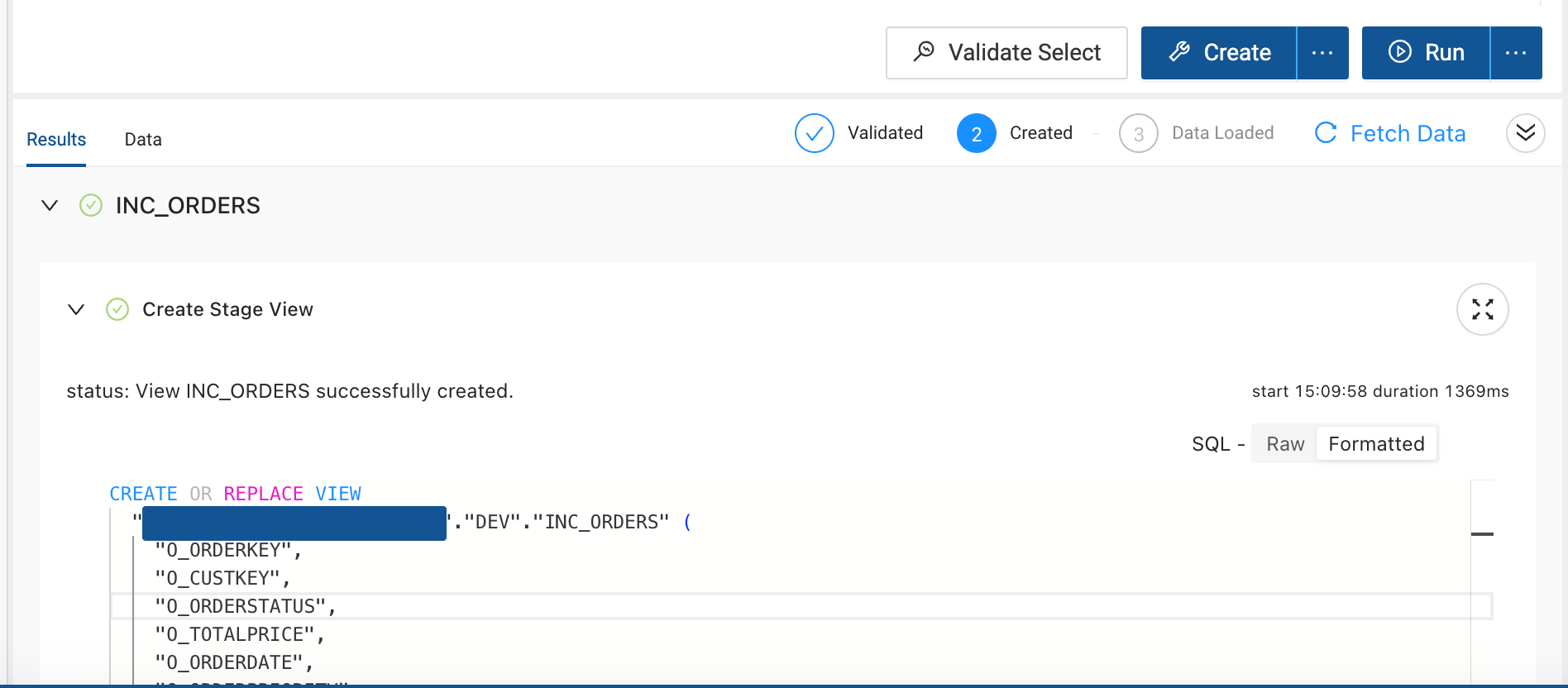
Click Create, to create the Incremental Node. You'll configure the Node in a later step.
Viewing SQLYou can always see the SQL that is executed by viewing the results.
-
Go back to the DAG and right click on the Incremental Node and select Add Node > Persistent Stage.
-
Open the Node Properties and make sure it’s not the same as the source Node. Make note of the Storage Location name.
-
Create and Run the Persistent Stage Node.
It’s best practice to add a Persistent Stage table to hold the historical data.
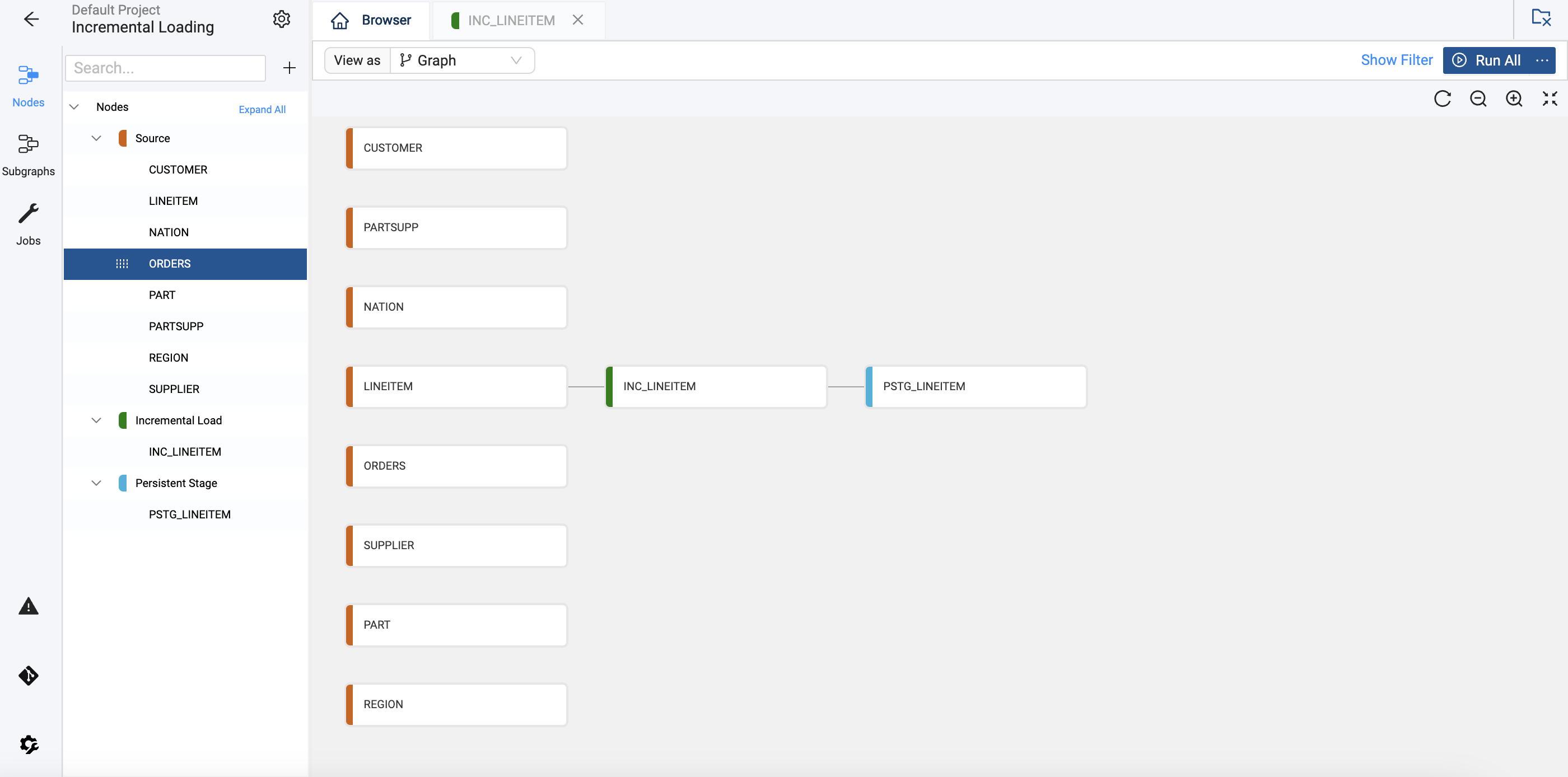
At this point your DAG should look similar to the image. The information in the Source Node changes, the Incremental Node only checks the changed information and the Persistent Stage holds the historical data.
Configure the Incremental Node
-
Open the Incremental Node and go to the Options.
-
Leave it as a view, toggle on the Filter data based on Persistent Table.
-
Enter the Storage Location of the Persistent Table. In this example, it’s
WORK. -
Enter the name of the Persistent Table. In this example, it’s
PSTG_LINEITEM. -
Change the Incremental Load Column to
L_SHIPDATE. This is the field that the table will use to determine if the data has changed.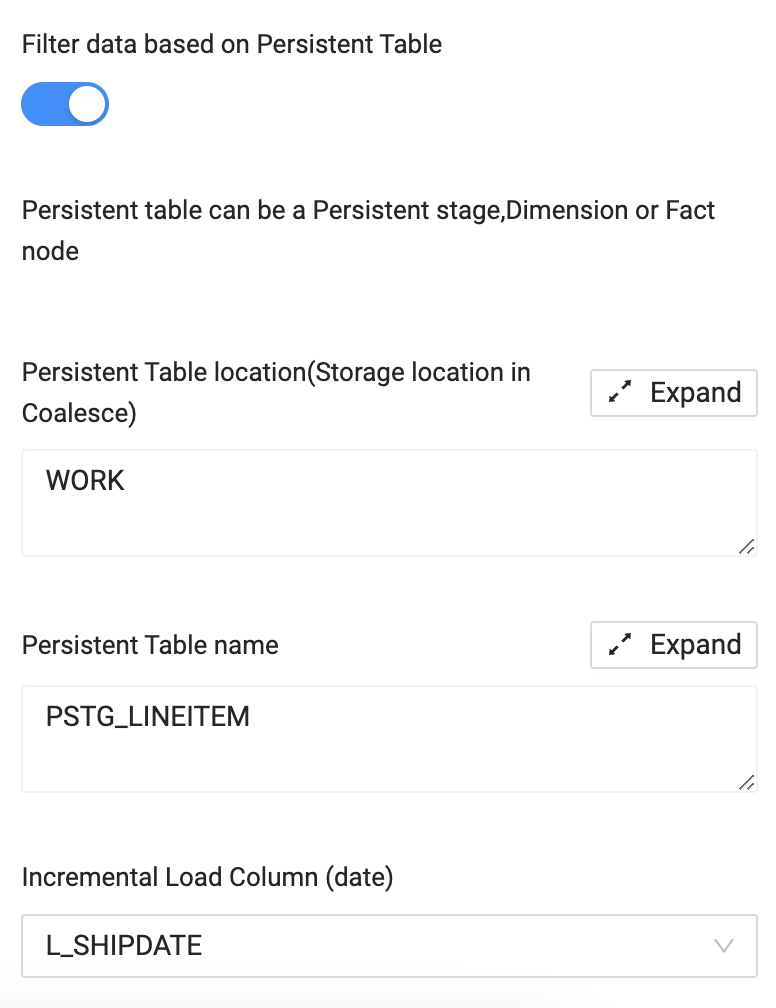
-
Go to the Join tab, click Generate Join, and Copy to Editor.
-
The query is looking for new or updated records in
LINEITEMthat have a ship date more recent than anything currently inPSTG_LINEITEM.FROM{{ ref('SAMPLE', 'LINEITEM') }} "LINEITEM"WHERE "LINEITEM"."L_SHIPDATE" >(SELECT COALESCE(MAX("L_SHIPDATE"), '1900-01-01')FROM {{ ref_no_link('WORK', 'PSTG_LINEITEM') }} )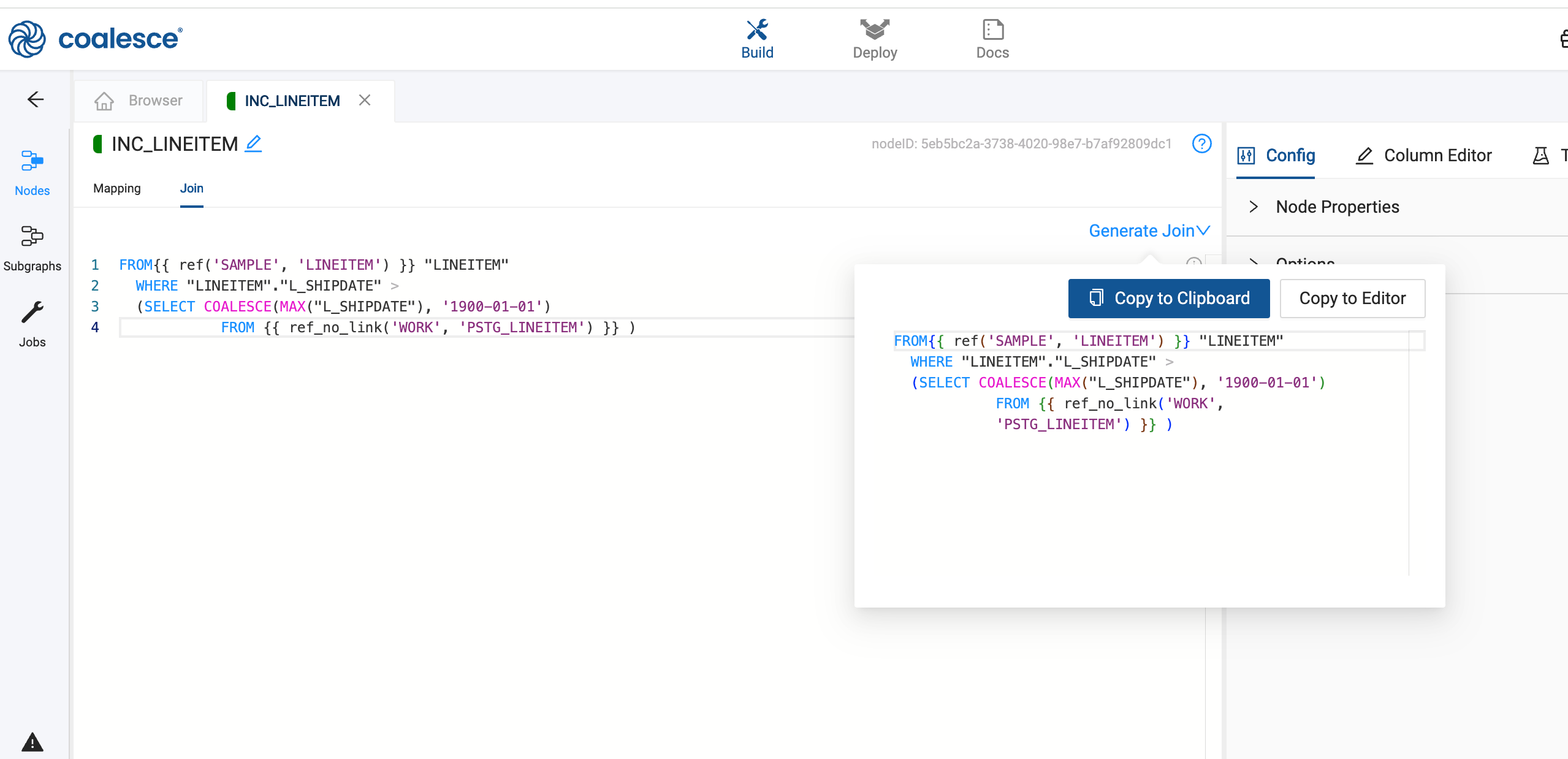
You've gone through the steps of settings up an Incremental Node that updates the data in a Persistent Table. The process is quick and easy.
Add Incremental Loading to an Existing Pipeline (Optional)
- Add the Incremental Node from the source Node you want to track.
- Either create or change an existing Stage Node to a Persistent Node Type.
- If you're updating an existing Node. You’ll need to do a few more things.
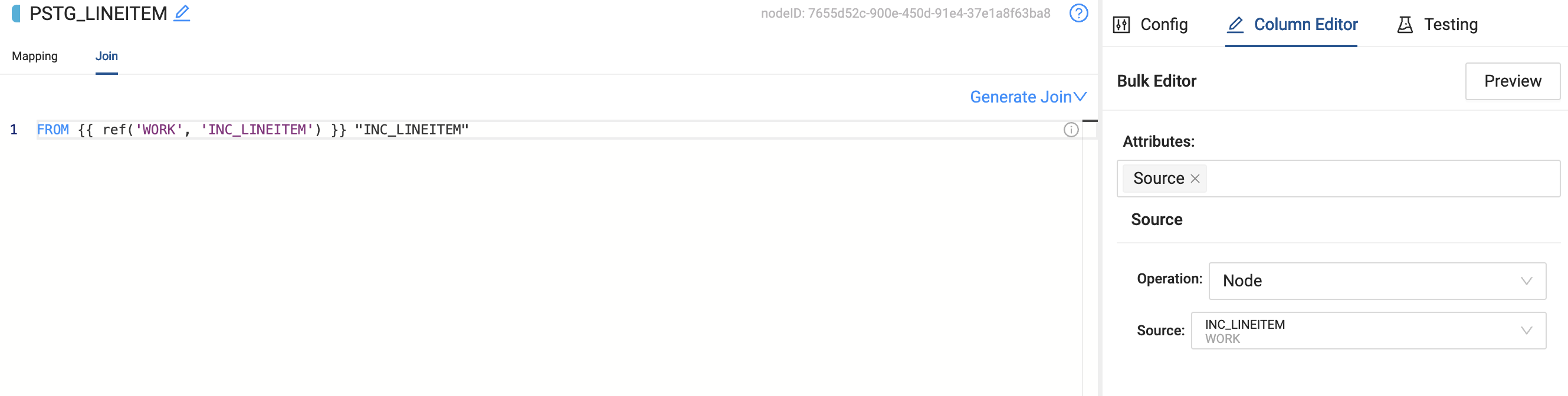
- Update the Persistent Node Type to reference the Incremental Node. You can do this by updating the Join to use the Incremental Node as the Source and changing the source in the columns.
Conclusion
Incremental loading is a vital strategy in data warehousing and ETL processes. It enhances efficiency by processing only new or updated data since the last load, significantly reducing load times and data transfer volumes. This approach ensures that target systems stay current with the latest information while minimizing resource usage.