Node Types
The Node Types section shows all the currently available node types that can be used.
All node types and nodes can be checked in to git and deployed to the environment.
Each node type is defined by a node specification YAML file, a Create Template and a Run Template.
The node specification consists of the following:
- Attributes of the node type (such as name prefix, graph color)
- UI elements that are used to configure the attributes of each individual instance of that node type
The Create Template for a node is executed during Deploy, while the Run Template is executed during Run/Refresh.
Coalesce comes with default Node Types which are not editable. However, they can be duplicated and edited, or new ones can be made from scratch.
To access Node Types, in your Workspace go to Build Settings > Node Types.
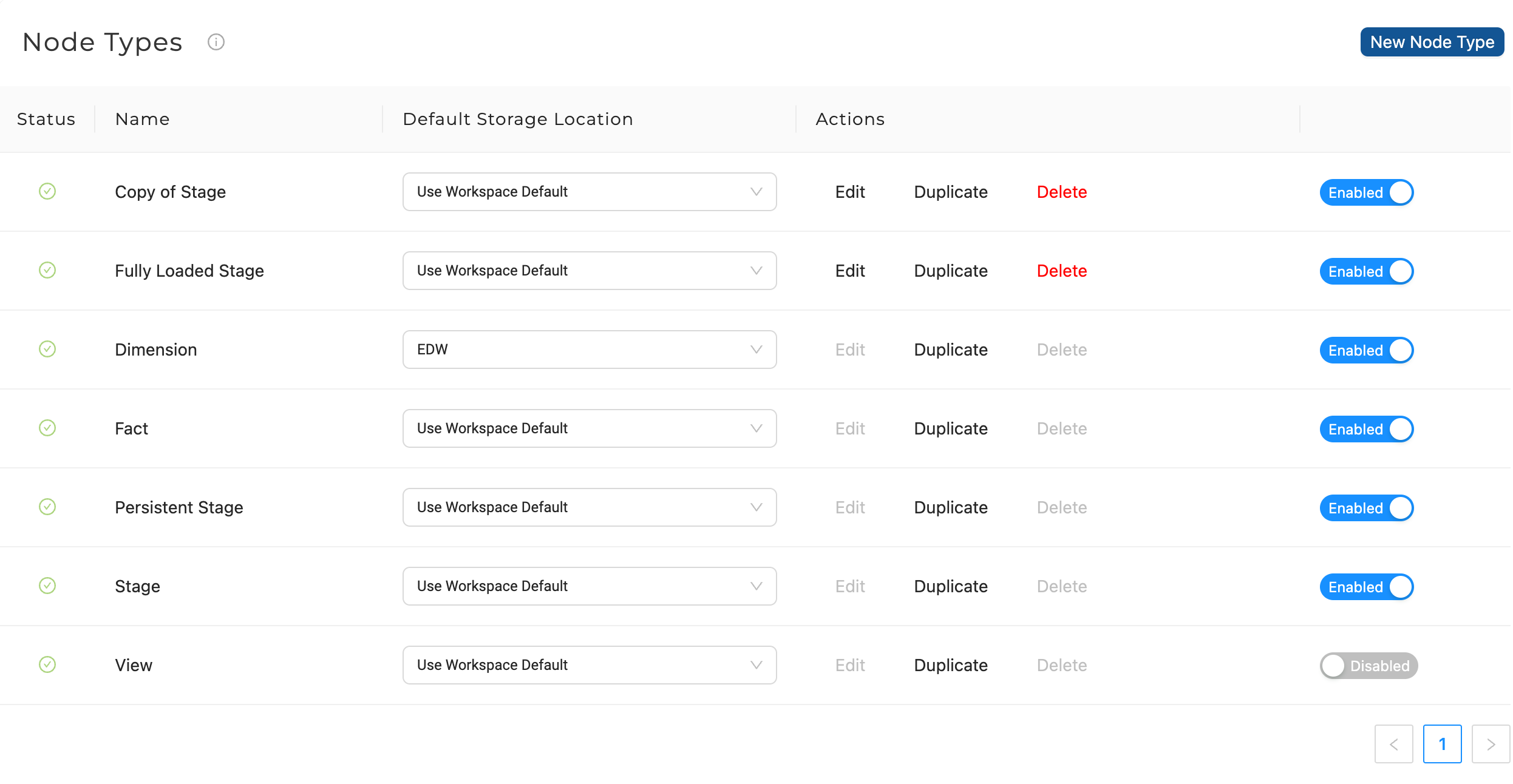
| Field | Description |
|---|---|
| Status | Green indicates all aspects of that node type are valid Red indicates there is invalid info within the node type that needs to be revised. |
| Name | This is the type of node. Coalesce provides the Dimension, Fact, Stage, View, and Persistent Stage node types, but a user can also create a new type. |
| Default Storage Location | Default storage location that will be chosen automatically for new nodes of this type. Each workspace will have a Global Default for all nodes, which can be overridden here. |
| Actions | All node types can be duplicated for further customization. The name of this duplicate will default to Copy of <Node Type> but can be modified in the Node Type Editor. Additionally, custom node types can be edited. Note: Default node types and node types in use in the application or node type editor cannot be deleted. |
| Enabled/Disabled | This feature allows a user to add any Enabled node types in the Node Graph. |
Default Node Types
Node types control the actual creation and data manipulation of all database objects within your data pipeline. Node types are defined by Jinja/SQL templates and a YAML Node definition which has numerous options for customization in the Node Type Editor.
Source Nodes
Source nodes represent the tables, external tables, or views where raw data is queried to be processed by subsequent nodes. They are the source tables that already exist in your data provider. They are not manually editable other than to change their location or add a description.
Stage Nodes
Stage nodes are intermediate nodes in the graph where you prepare the data by applying business logic.
By default, stage nodes truncate data before every run and always contain only the current batch of data. These nodes can be materialized into either a table or a view, but default to a table for easier troubleshooting.
Divide and conquer complex business logic by splitting it into multiple Stage Nodes.
Persistent Stage Nodes
Persistent stage nodes are similar to Stage Nodes, except that they:
- Do not truncate the data by default
- Persist data across multiple runs
- Support tracking change history of columns based on business key
Use Persistent Stage nodes when you want to keep the raw data for extended periods rather than just for the current batch load.
Fact Nodes
Fact nodes represent Coalesce's implementation of a Kimball Fact Table. A fact table consists of the measurements, metrics, or facts of a business process and is typically located at the center of a star schema or schema surrounded by dimension tables.
A fact table can be configured to use a business key to MERGE data at the appropriate grain of the data. Alternatively, if no business key is selected, the Fact Node will use an INSERT statement to populate the data.
You can read more about Fact Tables.
Dimension Nodes
Dimension nodes are generally descriptive in nature and describe Facts (see Fact Nodes above). For example time and location. They can also be used to store history.
A business key at the appropriate grain of the data is required for Dimension Nodes.
Supported Dimension Nodes
Coalesce currently supports Type 1 and Type 2 slowly changing dimensions.
- To create a Type 1 dimension (current state of the data) - do not choose a change tracking column.
- To create a Type 2 dimension (current and historical data) - do choose a change tracking column.
You can read more about Dimension Tables Core Concepts.
View Nodes
View nodes are used for creating a generic SQL VIEW. Many other node types can also be materialized as SQL VIEWs. The purpose of having this node type is for improved readability when looking at a DAG.
They are disabled by default but can be toggled in your Build Settings > Node Types.
User Defined Nodes
User Defined Nodes or UDNs are nodes that can be configured for your needs. Learn more in User Defined Nodes.
Package Nodes
After installing a package, you'll see the package listed under Node Types. Each package can contain multiple nodes and the type will always be the package name.