Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Coalesce Copilot
Coalesce Copilot is an AI assistant integrated into the Coalesce platform. It helps you build and modify data transformation pipelines using natural language. Instead of manually configuring Nodes through the Coalesce UI, you can describe your requirements in plain language. Copilot translates them into working DAG Nodes with transformations, columns, and relationships.
Think of it as a proficient Coalesce teammate. You describe your data needs in plain English or paste SQL, and Copilot translates that into actual DAG Nodes with proper transformations, columns, and relationships.
As with any AI-powered tool, Copilot is under active development. We regularly ship improvements based on feedback and testing, but you may occasionally encounter unexpected Node configurations, intermittent service interruptions, or changes to available capabilities as we refine features.
Always review generated Nodes and SQL before deployment. If Copilot becomes unresponsive, wait a few moments and start a new conversation in a fresh chat window.
Prerequisites
Before using Copilot, ensure you have:
- Access to Coalesce version 7.27 or later
- Active Workspace permissions to create and modify Nodes
- Version control checkpoint created before starting work with Copilot (recommended for easy rollback)
- Available Storage Locations (databases and schemas) configured in your Environment
Enable Copilot
Org administrators can go to Org Settings > Preferences and turn the features on or off for the whole organization. These features are not enabled by default. Reach out to your Coalesce account manager to sign up.
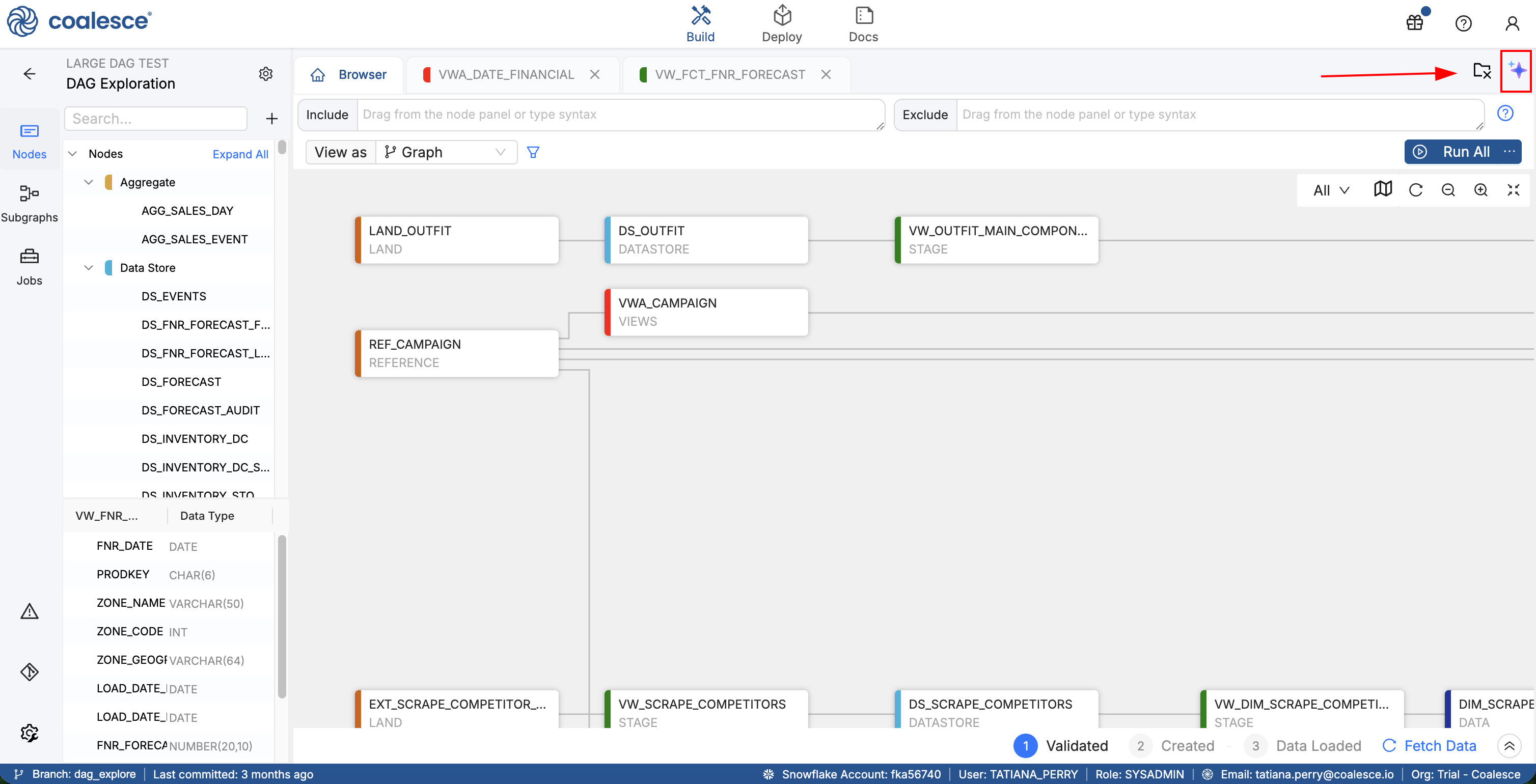
On your build tab, click the AI button  .
.
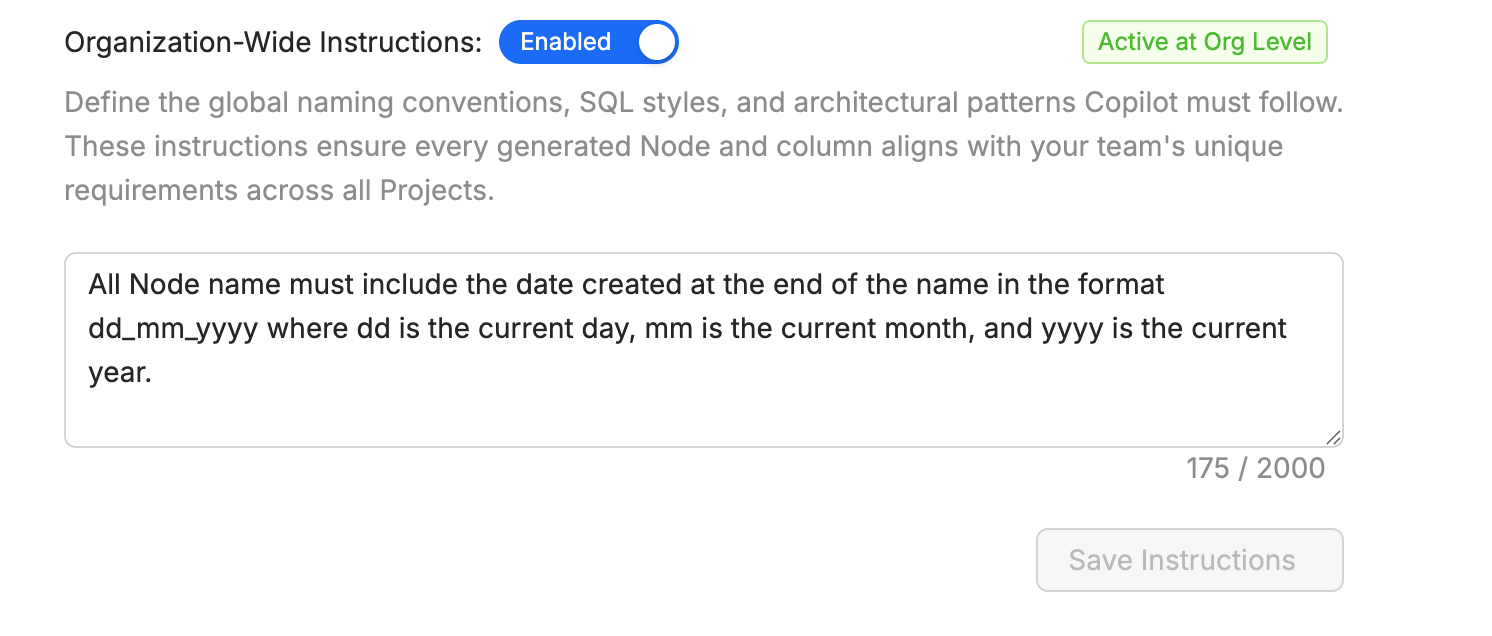
Organization-Wide Instructions
Set organization wide settings such as Node and column name standards and other standards.
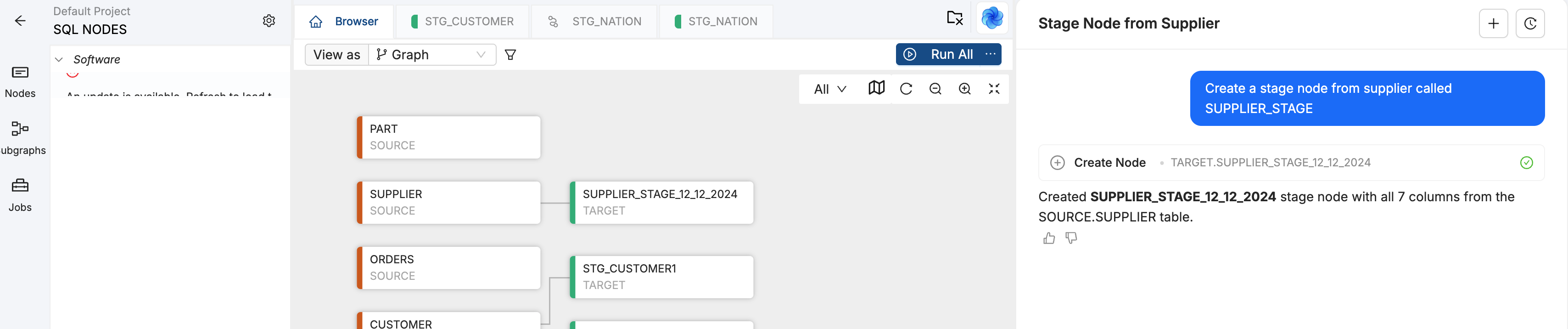
Project Level Instructions
Set project level settings such as Node and column name standards and other standards.
- Click on Project Settings > Copilot Instructions.
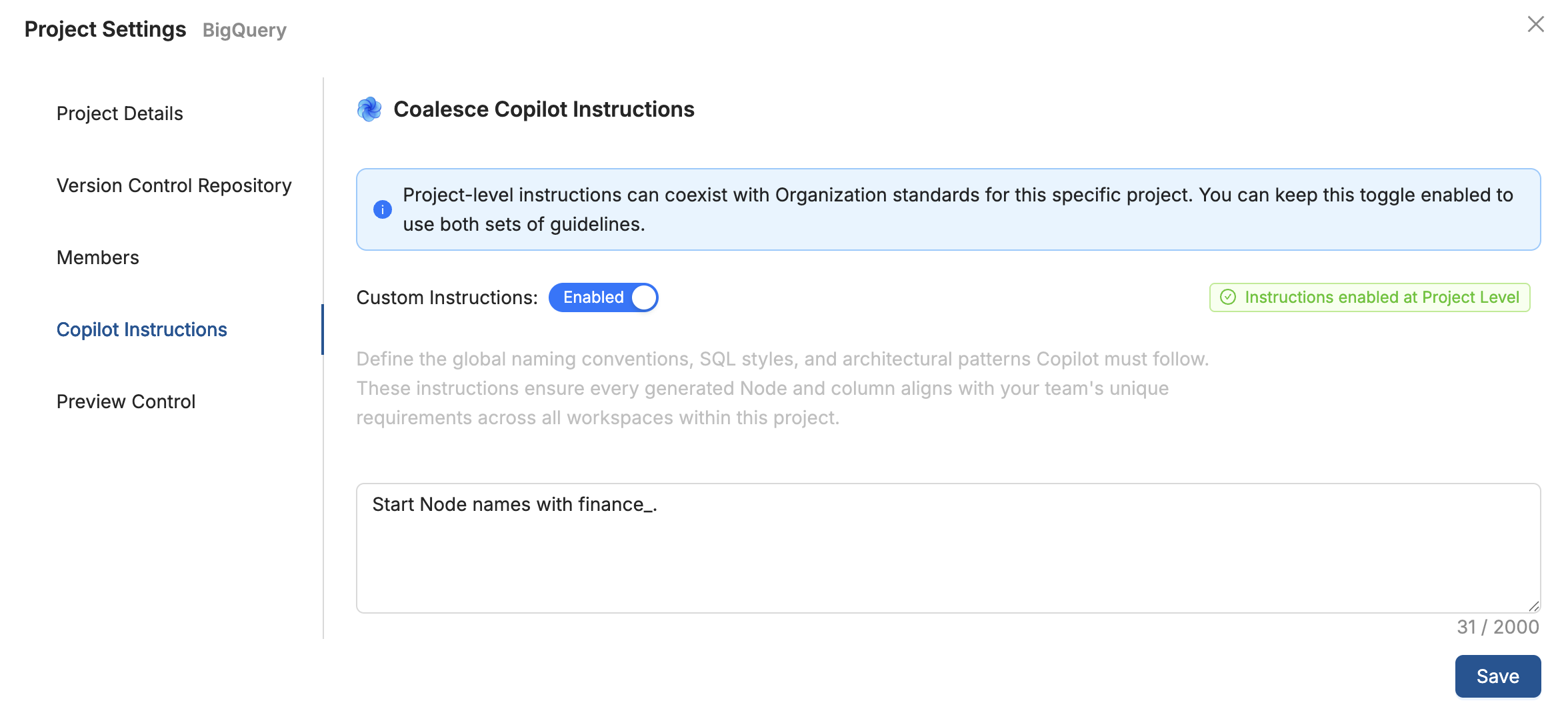
Organization level and project level work together. If there is a conflict Project level instructions take precedence.
Core Capabilities
Copilot can perform the following operations:
Build and Modify Nodes
- Create Nodes from natural language descriptions
- Add, remove, or update columns in existing Nodes
- Configure joins and relationships between Nodes
- Set business keys and system columns
Import SQL
- Convert existing SQL queries into Coalesce DAG Nodes
- Automatically create predecessor Nodes and dependencies
- Parse complex joins and aggregations into proper Node structures
Answer Questions
- Explain Workspace structure and Node configurations
- Provide guidance on Coalesce best practices
- Describe Node dependencies and column lineage
Multi-Step Operations
- Execute complex workflows requiring multiple Nodes
- Build complete pipelines from high-level requirements
Platform Awareness
- Adapts SQL syntax for Snowflake or Databricks
- Understands Coalesce-specific Node Types such as Stage, Dimension, Fact, View, and Persistent Stage
- Respects your Workspace context and existing Nodes
Operating Modes
Copilot has two operating modes that determine whether it modifies your Workspace or just provides information.
Edit Mode
Copilot makes actual changes to your Workspace. Use this mode when you want to build or modify Nodes.
What it does:
- Creates new Nodes and updates existing ones
- Imports SQL and executes multi-step operations
- Makes actual changes to your Workspace
Example prompts:
- "Create a customer dimension with these columns..."
- "Add a lifetime_value column to dim_customer"
- [Paste SQL query]
- "Build a complete customer 360 pipeline..."
Non-Edit Mode
Copilot provides answers, explanations, and recommendations without modifying your Workspace. This mode is safe for exploration and learning.
What it does:
- Answers questions about your Workspace
- Explains configurations and best practices
- Provides guidance without making changes
Example prompts:
- "What columns are in the sales_fact table?"
- "How should I structure a slowly changing dimension?"
- "Which Nodes depend on customer_dim?"
- "What's the difference between Persistent Stage and View?"
Communicating With Copilot
Copilot appears as a chat window in the Coalesce builder. Type your request naturally—no special syntax needed. The conversation is contextual, so you can have back-and-forth exchanges:
You: "Create a customer dimension"
Copilot: Creates dim_customer Node "I've created a customer dimension table. What columns would you like?"
You: "Add customer_id, name, email, and signup_date"
Copilot: Adds the columns "I've added those columns. Would you like me to set customer_id as the business key?"
Basic Workflow
- Create a version control checkpoint before starting with Copilot
- Open the Copilot chat in the Coalesce builder
- Type what you want to build or ask a question
- Review Copilot's actions in your Workspace
- Refine through follow-up messages if needed
- Deploy when ready
Example Prompt Workflows
Copilot adapts to different working styles. Choose the approach that fits your workflow.
- Start Simple and Add Details
- Copy Existing Structures
- Describe Your End Goal
- Import Existing SQL
This approach works well when you're exploring or aren't sure of all requirements upfront.
- "Create a basic customer dimension"
- Review the Node Copilot creates
- "Add loyalty_tier and lifetime_value columns"
- "Set customer_id as the business key"
Use this when you want consistency across similar Nodes or need to replicate a pattern.
- "Create a Node like dim_product but for stores"
- Copilot copies the structure
- "Update the columns to match store attributes"
This is fastest when you know exactly what you need and want Copilot to figure out the implementation.
- "I need to calculate monthly recurring revenue by customer segment"
- Copilot builds the entire pipeline
- Review and approve or request changes
Use this to migrate existing queries or logic into Coalesce.
- Paste your existing SQL query into the chat
- Copilot analyzes and creates necessary Nodes
- Review the generated DAG structure
- Adjust join logic or transformations as needed
Example 1: Creating a Dimension Node
Prompt:
"Create a dimension table for customers with customer_id as the business key. Include columns for customer_id, first_name, last_name, email, and signup_date."
What Copilot does:
- Creates a Dimension Node Type
- Adds specified columns with appropriate data types
- Sets customer_id as the business key
- Configures necessary predecessor relationships
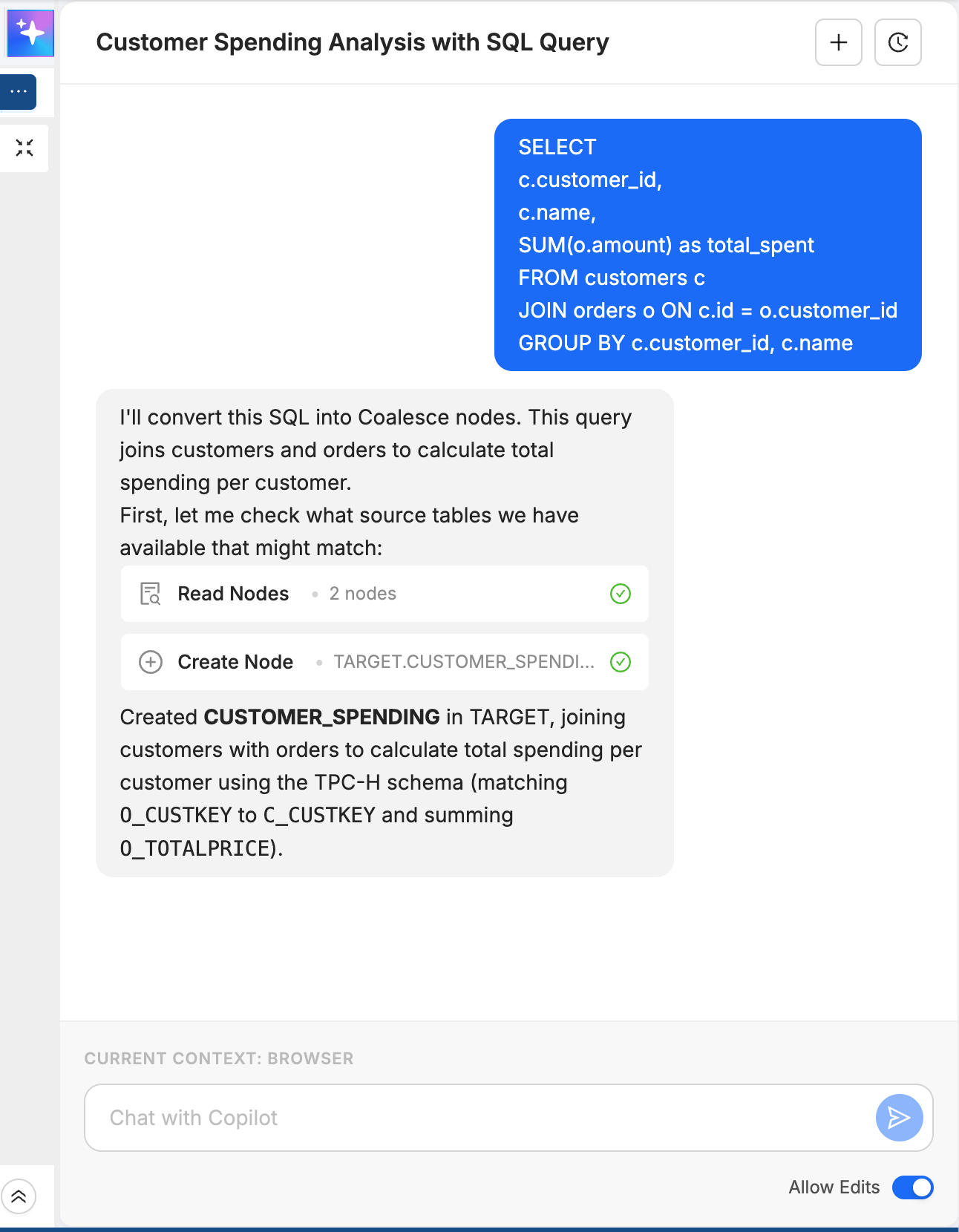
Example 2: Importing SQL
You can add SQL directly into Copilot.
Prompt:
SELECT
c.customer_id,
c.name,
SUM(o.amount) as total_spent
FROM customers c
JOIN orders o ON c.id = o.customer_id
GROUP BY c.customer_id, c.name
What Copilot does:
- Analyzes the SQL query
- Creates predecessor Nodes for customers and orders
- Builds a transformation Node with the join
- Sets up the aggregation logic
- Configures column mappings
Example 3: Multi-Step Pipeline
Prompt:
"Create a complete customer 360 view starting with raw customer data, add their order history, calculate lifetime value, and join with marketing campaign responses."
What Copilot does:
- Creates staging Nodes for raw data sources
- Builds dimension tables for customers
- Creates fact tables for orders and campaign responses
- Adds calculated columns for lifetime value
- Wires all Nodes together with proper relationships
Example 4: Modifying Existing Nodes
Prompt:
"Add a column called lifetime_value to dim_customer that calculates the sum of all order amounts for each customer."
What Copilot does:
- Finds the dim_customer Node
- Adds the new column
- Writes the aggregation logic
- References the appropriate predecessor Node for order data
What Copilot Knows About Your Workspace
Copilot Has Awareness Of
- Your current Workspace: All existing Nodes, their columns, and relationships
- Your data platform: Whether you're using Snowflake or Databricks, and adapts SQL syntax accordingly
- Available Node Types: How to build Dimension, Fact, View, and Persistent Stage
- Your Storage Locations: Which databases and schemas are available
- Your viewing context: Understands what you're currently looking at
What Copilot Doesn't Know
- Copilot doesn't see the actual data in your tables. It only sees metadata like Node names, columns, and schemas
- Data quality issues unless you describe them
- Query performance metrics or optimization opportunities based on runtime data
Getting Better Results
- Keep relevant Nodes visible in your Workspace
- Reference specific Node names using clear identifiers
- Mention target Subgraphs when organizing Nodes
- Ask questions about existing Nodes: "What columns are in sales_fact?"
- Request explanations: "Why did you choose a Persistent Stage instead of a View?"
- Get recommendations: "What's the best Node Type for aggregated metrics?"
When to Use Copilot Versus the Coalesce UI
| Use Copilot When | Use the Coalesce UI When |
|---|---|
| Building new Nodes from scratch | Fine-tuning individual column transformations with autocomplete |
| Converting existing SQL to Coalesce | Visual exploration of complex DAGs |
| Making bulk updates to multiple Nodes | Precise drag-and-drop column mapping |
| Learning Coalesce or exploring new features | Detailed configuration of advanced Node properties |
| Rapid prototyping and iteration | You prefer visual interfaces over conversation |
| You have clear requirements and want to save time | Making small tweaks where clicking is faster than typing |
| Working with standard Coalesce patterns |
Use both. Let Copilot build the structure quickly, then use the Coalesce UI for fine-tuning and visual validation. Teams often describe it as "Copilot for speed, Coalesce UI for polish."