Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Redshift
Grant access to your Redshift metadata to Catalog and run a few tests to verify the setup.
Requirements for Onboarding
You need specific permissions to finish onboarding. You should be a super user who can impersonate all schema owners.
When new schemas are created after onboarding, re-run the grant procedures in section 2.4.
What Catalog Does With This Access
- Catalog is granted USAGE on all schemas and REFERENCES on all tables. That is the minimum access Catalog needs to read your metadata without accessing your table data.
- Catalog is also granted unrestricted SYSLOG access. Catalog needs SYSLOG to view queries run against tables.
More Information
For details on privileges, access control, and user creation, see the AWS documentation:
- Privileges and access documentation
- User creation and access to system tables
- SYSLOG and visibility of data in system tables and views
1. Whitelist Catalog's IP on Redshift
To allow Catalog to connect to Redshift, whitelist Catalog's IP address.
Catalog uses these fixed IPs:
- For instances on US Catalog app, use
34.42.92.72. - For instances on EU Catalog app, use
35.246.176.138.
How To Whitelist an IP on Redshift
- From the Redshift Dashboard, click Clusters.
- In the list of clusters, choose your cluster.
- In the Configuration tab of the clusters detail page, under the VPC Security Groups section, click the name of the security group.
- In the security group view, select the Inbound tab on the bottom half of the page, then in that tab click Edit.
- In the Edit inbound rules dialog, add the IP addresses that Catalog can use to access the cluster. To add a new rule, click Add Rule at the bottom of the list, and set the IP address for your Catalog hostname.
2. Create Catalog User on Redshift
You'll enter credentials in the Coalesce App. Follow these steps to create them, or run the SQL below. For the full script in one place, see Full SQL procedure in the Appendix.
2.1 Create Procedure To Grant Rights on Existing Schemas
The procedure grants USAGE, CREATE, and REFERENCES on all schemas that exist when you run it, plus REFERENCES on all tables in those schemas.
- CREATE rights are required so REFERENCES can work.
- REFERENCES rights are required for Catalog to see column names.
Catalog won't create schemas or reference foreign keys with these grants alone.
CREATE OR REPLACE PROCEDURE grant_rights_schema_today(user_name VARCHAR)
AS $$
DECLARE
row record;
sch text;
BEGIN
FOR row IN (
SELECT nspname
FROM pg_namespace
WHERE nspname NOT LIKE 'pg_%'
AND nspname != 'information_schema'
) LOOP
sch := row.nspname;
EXECUTE 'GRANT USAGE ON SCHEMA ' || sch || ' TO "' || user_name || '"';
EXECUTE 'GRANT CREATE ON SCHEMA ' || sch || ' TO "' || user_name || '"';
EXECUTE 'GRANT REFERENCES ON ALL TABLES IN SCHEMA ' || sch || ' TO "' || user_name || '"';
END LOOP;
END;
$$ LANGUAGE plpgsql;
2.2 Create Procedure To Grant Default Privileges on Future Tables
The procedure sets default REFERENCES on new tables created in schemas that already appear in pg_tables when you run it. ALTER DEFAULT PRIVILEGES applies to tables within a named schema. It does not grant schema-level USAGE and does not cover schemas you create later.
For each schema, the procedure runs as the schema owner. Only the schema owner can define default privileges for objects they create.
CREATE OR REPLACE PROCEDURE grant_rights_schema_future(user_name VARCHAR)
AS $$
DECLARE
row record;
usr text;
sch text;
BEGIN
FOR row IN (
SELECT distinct tableowner,schemaname
FROM pg_tables
WHERE schemaname not LIKE 'pg_%'
AND schemaname != 'information_schema'
) LOOP
sch := row.schemaname;
usr := row.tableowner;
EXECUTE 'ALTER DEFAULT PRIVILEGES FOR USER "' || usr || '" IN SCHEMA ' || sch
|| ' GRANT REFERENCES ON TABLES TO "' || user_name || '"';
END LOOP;
END;
$$ LANGUAGE plpgsql;
Here is an example statement from the loop for schema tesla owned by user elon: ALTER DEFAULT PRIVILEGES FOR USER elon IN SCHEMA tesla GRANT REFERENCES ON TABLES TO castor
When tooling such as dbt or Hightouch creates a new schema after onboarding, re-run both procedures in section 2.4, or grant on each new schema manually.
This matters most for late-binding views (CREATE VIEW ... WITH NO SCHEMA BINDING, the default for dbt-redshift). Redshift resolves their columns live at query time. Catalog needs USAGE on every schema the view reads from to extract those columns. Without it, the view can appear in Catalog with no columns, even though table metadata still ingests normally.
dbt and other Catalog integrations enrich metadata already extracted from Redshift. If the warehouse extraction returns no columns, integration column descriptions won't appear in Catalog either.
2.3 Create Catalog User
The Catalog user must have SYSLOG access. Use a safe password, from a password manager for example.
CREATE USER "castor"
PASSWORD '<password>'
SYSLOG ACCESS UNRESTRICTED;
2.4 Grant Rights to Catalog User
Grant rights with the procedures in sections 2.1 and 2.2, then run the following commands.
Run both commands whenever a new schema is created if you want Catalog to ingest it.
CALL grant_rights_schema_today('castor');
CALL grant_rights_schema_future('castor');
For a single new schema, you can grant explicitly instead of re-running the procedures across all schemas:
GRANT USAGE ON SCHEMA your_new_schema TO "castor";
GRANT CREATE ON SCHEMA your_new_schema TO "castor";
GRANT REFERENCES ON ALL TABLES IN SCHEMA your_new_schema TO "castor";
CALL grant_rights_schema_future('castor');
The future-tables procedure only includes schemas that have at least one table in pg_tables. If you create an empty schema first, re-run grant_rights_schema_future after the first table is created.
3. Test the Catalog User
The Catalog user should now be correctly set up. Before you give Catalog the credentials, run a test to make sure everything works.
- Connect to your Redshift cluster using the
castorcredentials you created. - Run the following checks:
3.1 Check Schemas the Catalog User Can See
SELECT
db.oid AS database_id,
db.datname AS database_name,
n.oid::TEXT AS schema_id,
n.nspname AS schema_name,
u.usename AS schema_owner,
u.usesysid AS schema_owner_id,
sd.description AS comment
FROM pg_catalog.pg_namespace AS n
CROSS JOIN pg_catalog.pg_database AS db
JOIN pg_catalog.pg_user u ON u.usesysid = n.nspowner
LEFT JOIN pg_catalog.pg_description sd ON sd.classoid = n.oid
WHERE TRUE
AND db.datname = CURRENT_DATABASE()
AND n.nspname NOT LIKE 'pg_%%'
AND n.nspname NOT IN ('catalog_history', 'information_schema')
You should see all of your Redshift schemas.
3.2 Check Queries the Catalog User Can See
SELECT
q.query::VARCHAR(128) AS query_id,
q.querytxt::VARCHAR(20000) AS query_text,
db.oid AS database_id,
q.database AS database_name,
q.pid AS process_id,
q.aborted,
q.starttime AS start_time,
q.endtime AS end_time,
q.userid AS user_id,
q.label
FROM pg_catalog.stl_query AS q
JOIN pg_catalog.pg_database AS db ON db.datname = q.database
WHERE q.starttime > CURRENT_TIMESTAMP - INTERVAL '6 hours'
LIMIT 1000
You should get queries from different users.
4. Add Credentials in the Coalesce App
You must be a Catalog admin to add integration credentials.
You can now enter the credentials you created in the Coalesce App.
- Go to Settings > Integrations.
- Click Redshift, then Add.
- Enter the credentials.
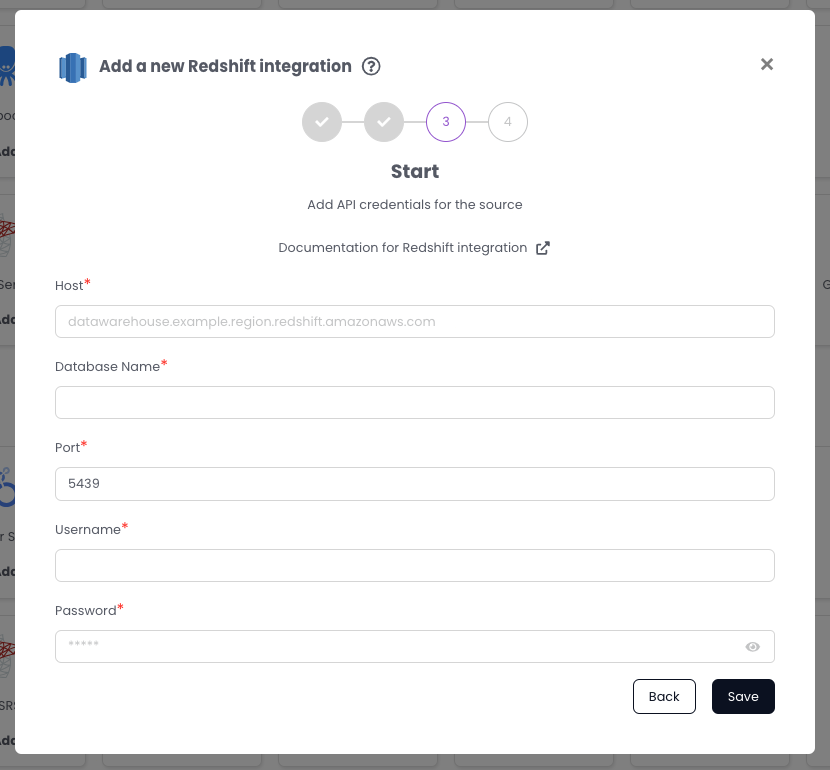
Troubleshooting
These scenarios cover common Redshift onboarding and ingestion questions for Catalog.
Catalog Shows Fewer Tables or Columns Than Expected
The Catalog user needs USAGE on schemas and REFERENCES on tables for full metadata visibility. New schemas created after onboarding do not inherit grants automatically. Re-running only the future-tables procedure is not enough, because it does not grant schema-level USAGE.
Resolution:
- Re-run both procedures from section 2.4 for schemas added after onboarding, or run the per-schema grants shown there.
- If a view appears with no columns, check whether it's a late-binding view and whether the Catalog user has USAGE on every underlying schema.
- Confirm USAGE, CREATE, and REFERENCES grants completed without errors in Redshift.
- If specific schemas stay empty, verify the Catalog user can see them when logged into Redshift with the same credentials stored in Catalog.
- Wait for the next Catalog ingestion cycle, or contact Coalesce Support if metadata still looks incomplete.
Query Text or Lineage Looks Incomplete
Catalog reads STL_QUERY and related system views for workload insight. Restricted SYSLOG visibility limits what Catalog can associate with tables.
Resolution:
- Confirm the Catalog user still has the SYSLOG-related access described under What Catalog Does With This Access.
- Check whether recent queries appear in
STL_QUERYfor the same database Catalog monitors. - For persistent gaps, contact Coalesce Support with a sample table name and time window.
You Moved or Duplicated Environments, For Example During Cloud Migration
Pinned assets, favorites, or warehouse naming may change when you migrate from one engine to another. Catalog ties assets to the identifiers it ingests from Redshift.
Resolution:
- Align Catalog integration credentials with the cluster that now hosts the canonical schema names.
- Plan a fresh ingestion cycle after go-live and validate counts of databases and schemas in Catalog against Redshift.
- Work with Coalesce Support when you need help remapping or reconciling large moves between warehouses.
Connection Failures After an IP or Security Group Change
Catalog connects from fixed egress IPs. Cluster security groups must still allow those addresses.
Resolution:
- Re-check the steps under 1. Whitelist Catalog's IP on Redshift and add both IPs for your Catalog hostname if any rule was replaced during maintenance.
- Test connectivity from a controlled environment if your team uses network traces.
- Update stored credentials in Catalog if the cluster endpoint or port changed.
New Cluster or Restored Snapshot
Restored clusters often use new endpoints, passwords, or parameter groups.
Resolution:
- Update Settings > Integrations in Catalog with the new host, database, user, and password.
- Re-run the 3. Test the Catalog User SQL from this page to confirm metadata queries succeed.
- Schedule a full ingestion refresh if the cluster ID changed materially.
Appendix
Full Code
-- Create procedure to grant rights on existing schemas
CREATE OR REPLACE PROCEDURE grant_rights_schema_today(user_name VARCHAR)
AS $$
DECLARE
row record;
sch text;
BEGIN
FOR row IN (
SELECT nspname
FROM pg_namespace
WHERE nspname NOT LIKE 'pg_%'
AND nspname != 'information_schema'
) LOOP
sch := row.nspname;
EXECUTE 'GRANT USAGE ON SCHEMA ' || sch || ' TO "' || user_name || '"';
-- Create is needed references to work
EXECUTE 'GRANT CREATE ON SCHEMA ' || sch || ' TO "' || user_name || '"';
-- References allow the catalog user to see column names
-- It also allows it to reference foreign keys, but we will never do that
EXECUTE 'GRANT REFERENCES ON ALL TABLES IN SCHEMA ' || sch || ' TO "' || user_name || '"';
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- Create procedure to grant default privileges on future tables in existing schemas
CREATE OR REPLACE PROCEDURE grant_rights_schema_future(user_name VARCHAR)
AS $$
DECLARE
row record;
usr text;
sch text;
BEGIN
FOR row IN (
SELECT distinct tableowner,schemaname
FROM pg_tables
WHERE schemaname not LIKE 'pg_%'
AND schemaname != 'information_schema'
) LOOP
sch := row.schemaname;
usr := row.tableowner;
EXECUTE 'ALTER DEFAULT PRIVILEGES FOR USER "' || usr || '" IN SCHEMA ' || sch
|| ' GRANT REFERENCES ON TABLES TO "' || user_name || '"';
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- Create Catalog User
CREATE USER "castor"
PASSWORD '<password>'
SYSLOG ACCESS UNRESTRICTED;
-- Grant rights to Castor user
CALL grant_rights_schema_today('castor');
CALL grant_rights_schema_future('castor');
Queries Run by the Catalog User
- Databases
SELECT
db.oid AS database_id,
db.datname AS database_name,
dd.description AS "comment"
FROM pg_catalog.pg_database AS db
LEFT JOIN pg_catalog.pg_description AS dd ON dd.classoid = db.oid
-- when cross database query goes public this will evolve
WHERE db.datname = CURRENT_DATABASE()
- Schemas
SELECT
db.oid AS database_id,
db.datname AS database_name,
n.oid::TEXT AS schema_id,
n.nspname AS schema_name,
u.usename AS schema_owner,
u.usesysid AS schema_owner_id,
sd.description AS "comment"
FROM pg_catalog.pg_namespace AS n
CROSS JOIN pg_catalog.pg_database AS db
JOIN pg_catalog.pg_user AS u ON u.usesysid = n.nspowner
LEFT JOIN pg_catalog.pg_description AS sd ON sd.classoid = n.oid
WHERE TRUE
AND db.datname = CURRENT_DATABASE()
AND n.nspname NOT LIKE 'pg_%%'
AND n.nspname NOT IN ('catalog_history', 'information_schema')
- Tables
WITH tables AS (
SELECT
t.oid AS table_id,
t.relname AS table_name,
n.nspname AS schema_name,
n.oid AS schema_id,
u.usename AS table_owner,
t.relowner AS table_owner_id,
td.description AS "comment",
t.reltuples::BIGINT AS tuples
FROM pg_class AS t
CROSS JOIN parameters AS p
JOIN pg_catalog.pg_namespace AS n ON n.oid = t.relnamespace
LEFT JOIN pg_catalog.pg_description AS td ON td.objoid = t.oid AND td.objsubid = 0
LEFT JOIN pg_catalog.pg_user AS u ON u.usesysid = t.relowner
WHERE TRUE
AND t.relam IN (0, 2) -- should not be an index
),
database AS (
SELECT
db.datname AS database_name,
db.oid AS database_id
FROM pg_catalog.pg_database AS db
WHERE TRUE
AND db.datname = CURRENT_DATABASE()
LIMIT 1
),
meta AS (
SELECT
t.table_schema AS schema_name,
t.table_name AS table_name,
t.table_type
FROM information_schema.tables AS t
CROSS JOIN parameters AS p
WHERE TRUE
),
external_tables AS (
SELECT
db.datname AS database_name,
db.oid::TEXT AS database_id,
s.schemaname AS schema_name,
s.esoid::TEXT AS schema_id,
t.tablename AS table_name,
db.datname || '.' || s.schemaname || '.' || t.tablename AS table_id,
u.usename AS table_owner,
s.esowner AS table_owner_id,
NULL AS tuples,
NULL AS "comment",
'EXTERNAL' AS table_type
FROM SVV_EXTERNAL_TABLES AS t
JOIN SVV_EXTERNAL_SCHEMAS AS s ON t.schemaname = s.schemaname
JOIN pg_catalog.pg_user AS u ON s.esowner = u.usesysid
JOIN pg_catalog.pg_database AS db ON CURRENT_DATABASE() = db.datname
)
SELECT
d.database_name,
d.database_id::TEXT AS database_id,
t.schema_name,
t.schema_id::TEXT AS schema_id,
t.table_name,
t.table_id::TEXT AS table_id,
t.table_owner,
t.table_owner_id,
t.tuples,
t.comment,
COALESCE(m.table_type, 'BASE TABLE') AS table_type
FROM tables AS t
CROSS JOIN database AS d
LEFT JOIN meta AS m ON (t.table_name = m.table_name AND t.schema_name = m.schema_name)
UNION DISTINCT
SELECT * FROM external_tables
- Columns
WITH ids AS (
SELECT
db.datname AS database_name,
db.oid AS database_id,
t.oid AS table_id,
t.relname AS table_name,
n.nspname AS schema_name,
n.oid AS schema_id
FROM pg_class AS t
JOIN pg_catalog.pg_namespace AS n ON n.oid = t.relnamespace
CROSS JOIN pg_catalog.pg_database AS db
WHERE TRUE
AND db.datname = CURRENT_DATABASE()
AND n.nspname NOT LIKE 'pg_%%'
AND n.nspname NOT IN ('catalog_history', 'information_schema')
AND t.relam IN (0, 2) -- should not be an index
),
information_tables AS (
SELECT
i.database_name,
i.database_id,
c.table_schema AS schema_name,
i.schema_id,
c.table_name AS table_name,
i.table_id,
c.column_name,
i.table_id || '.' || c.column_name AS column_id,
c.data_type,
c.ordinal_position,
c.column_default,
c.is_nullable,
c.character_maximum_length,
c.character_octet_length,
c.numeric_precision,
c.numeric_precision_radix,
c.numeric_scale,
c.datetime_precision,
c.interval_precision,
c.interval_type,
d.description AS "comment"
FROM information_schema.columns AS c
JOIN ids AS i
ON c.table_schema = i.schema_name AND c.table_name = i.table_name
LEFT JOIN pg_catalog.pg_description AS d
ON d.objoid = i.table_id AND d.objsubid = c.ordinal_position
),
raw_tables AS (
-- some table might be missing from information_schema.columns
-- this is a fallback fetching from lower level pg tables
SELECT
i.database_name,
i.database_id,
n.nspname AS schema_name,
n.oid AS schema_id,
c.relname AS table_name,
c.oid AS table_id,
a.attname AS column_name,
c.oid::TEXT || '.' || a.attname AS column_id,
a.attnum AS ordinal_position,
ad.adsrc AS column_default,
CASE
WHEN t.typname = 'bpchar' THEN 'char'
ELSE t.typname
END AS data_type,
CASE a.attnotnull WHEN TRUE THEN 'NO' ELSE 'YES' END AS is_nullable
FROM pg_attribute AS a
JOIN pg_type AS t ON t.oid = a.atttypid -- type
JOIN pg_class AS c ON c.oid = a.attrelid -- table
LEFT JOIN pg_attrdef AS ad ON ( ad.adrelid = c.oid AND ad.adnum = a.attnum ) -- default
JOIN pg_namespace AS n ON n.oid = c.relnamespace -- schema
JOIN ids AS i ON n.nspname = i.schema_name AND c.relname = i.table_name -- database
WHERE TRUE
AND c.relname NOT LIKE '%%pkey'
AND a.attnum >= 0
AND t.typname NOT IN ('xid', 'cid', 'oid', 'tid', 'name')
),
tables AS (
SELECT
COALESCE(i.database_name, r.database_name) AS database_name,
COALESCE(i.database_id, r.database_id)::TEXT AS database_id,
COALESCE(i.schema_name, r.schema_name) AS schema_name,
COALESCE(i.schema_id, r.schema_id)::TEXT AS schema_id,
COALESCE(i.table_name, r.table_name) AS table_name,
COALESCE(i.table_id, r.table_id)::TEXT AS table_id,
COALESCE(i.column_name, r.column_name) AS column_name,
COALESCE(i.column_id, r.column_id) AS column_id,
COALESCE(i.data_type, r.data_type) AS data_type,
COALESCE(i.ordinal_position, r.ordinal_position) AS ordinal_position,
COALESCE(i.is_nullable, r.is_nullable) AS is_nullable,
COALESCE(i.column_default, r.column_default) AS column_default,
i.character_maximum_length::INT AS character_maximum_length,
i.character_octet_length::INT AS character_octet_length,
i.numeric_precision::INT AS numeric_precision,
i.numeric_precision_radix::INT AS numeric_precision_radix,
i.numeric_scale::INT AS numeric_scale,
i.datetime_precision::INT AS datetime_precision,
i.interval_precision::TEXT AS interval_precision,
i.interval_type::TEXT AS interval_type,
i.comment::TEXT AS "comment"
FROM raw_tables AS r
LEFT JOIN information_tables AS i ON (i.table_id = r.table_id AND i.column_name = r.column_name)
),
views_late_binding AS (
SELECT
i.database_name,
i.database_id::TEXT AS database_id,
c.schema_name,
i.schema_id::TEXT AS schema_id,
c.table_name,
i.table_id::TEXT AS table_id,
c.column_name,
i.table_id::TEXT || '.' || c.column_name AS column_id,
c.data_type,
c.ordinal_position,
'YES' AS is_nullable,
NULL::TEXT AS column_default,
NULL::INT AS character_maximum_length,
NULL::INT AS character_octet_length,
NULL::INT AS numeric_precision,
NULL::INT AS numeric_precision_radix,
NULL::INT AS numeric_scale,
NULL::INT AS datetime_precision,
NULL::TEXT AS interval_precision,
NULL::TEXT AS interval_type,
NULL::TEXT AS "comment"
FROM (
SELECT
schema_name,
table_name,
column_name,
MIN(data_type) AS data_type,
MIN(ordinal_position) AS ordinal_position
FROM PG_GET_LATE_BINDING_VIEW_COLS()
-- syntax specific to this redshift system table
COLS(
schema_name NAME,
table_name NAME,
column_name NAME,
data_type VARCHAR,
ordinal_position INT
)
GROUP BY 1, 2, 3
) AS c
JOIN ids AS i
ON c.schema_name = i.schema_name AND c.table_name = i.table_name
),
external_columns AS (
SELECT
db.datname AS database_name,
db.oid::TEXT AS database_id,
s.schemaname AS schema_name,
s.esoid::TEXT AS schema_id,
c.tablename AS table_name,
db.datname || '.' || s.schemaname || '.' || c.tablename AS table_id,
c.columnname AS column_name,
db.datname || '.' || s.schemaname || '.' || c.tablename || '.' || c.columnname AS column_id,
c.external_type AS data_type,
MIN(c.columnnum) AS ordinal_position,
CASE c.is_nullable WHEN 'false' THEN 'NO' ELSE 'YES' END AS is_nullable,
NULL AS column_default,
NULL AS character_maximum_length,
NULL AS character_octet_length,
NULL AS numeric_precision,
NULL AS numeric_precision_radix,
NULL AS numeric_scale,
NULL AS datetime_precision,
NULL AS interval_precision,
NULL AS interval_type,
NULL AS "comment"
FROM SVV_EXTERNAL_COLUMNS AS c
JOIN SVV_EXTERNAL_SCHEMAS AS s ON c.schemaname = s.schemaname
JOIN pg_catalog.pg_database AS db ON CURRENT_DATABASE() = db.datname
-- To remove duplicate column names that can occur in external tables (no check on CSVs)
GROUP BY database_name, database_id, schema_name, schema_id, table_name, table_id, column_name, column_id, data_type, is_nullable
)
SELECT * FROM tables
UNION DISTINCT
SELECT * FROM views_late_binding
UNION DISTINCT
SELECT * FROM external_columns
- Users
SELECT
usename AS user_name,
usesysid AS user_id,
usecreatedb AS has_create_db,
usesuper AS is_super,
valuntil AS valid_until
FROM pg_catalog.pg_user
- Groups
SELECT
groname AS group_name,
grosysid AS group_id,
grosysid AS group_list
FROM pg_group
- Queries
WITH parameters AS (
SELECT
DATEADD(DAY,-1,CURRENT_DATE) AS day_start,
0 AS hour_min,
23 AS hour_max
),
queries_deduplicated AS (
SELECT DISTINCT q.query
FROM pg_catalog.stl_query AS q
CROSS JOIN parameters AS p
WHERE TRUE
AND DATE(q.starttime) = p.day_start
AND EXTRACT('hour' FROM q.starttime) BETWEEN p.hour_min AND p.hour_max
),
query AS (
SELECT
q.query,
qt.text,
qt.sequence,
COUNT(*) OVER(PARTITION BY q.query) AS sequence_count
FROM queries_deduplicated AS q
INNER JOIN pg_catalog.stl_querytext AS qt ON q.query = qt.query
),
raw_query_text AS
(
SELECT
q.query,
LISTAGG(q.text, '') WITHIN GROUP (ORDER BY q.sequence) AS agg_text
FROM query AS q
WHERE TRUE
-- LISTAGG raises an error when total length >= 65535
-- each sequence contains 200 char max
AND q.sequence_count < (65535 / 200)
GROUP BY q.query
),
query_text AS (
SELECT
query,
CASE
WHEN agg_text ILIKE 'INSERT INTO%%'
THEN REGEXP_REPLACE(agg_text, 'VALUES (.*)', 'DEFAULT VALUES')
ELSE agg_text
END AS agg_text
FROM raw_query_text
),
read_query AS (
SELECT
q.query::VARCHAR(256) AS query_id,
qt.agg_text::VARCHAR(60000) AS query_text,
db.oid AS database_id,
q.database AS database_name,
q.pid AS process_id,
q.aborted,
q.starttime AS start_time,
q.endtime AS end_time,
q.userid AS user_id,
q.label
FROM pg_catalog.stl_query AS q
JOIN query_text AS qt ON q.query = qt.query
JOIN pg_catalog.pg_database AS db ON db.datname = q.database
CROSS JOIN parameters AS p
WHERE TRUE
AND DATE(q.starttime) = p.day_start
AND EXTRACT('hour' FROM q.starttime) BETWEEN p.hour_min AND p.hour_max
),
-- the DDL part is sensible to any change of JOIN and AGGREGATION: test in the field prior to merging
ddl_query AS (
SELECT
(q.xid || '-' || q.query_part_rank)::VARCHAR(256) AS query_id,
q.query_text::VARCHAR(20000) AS query_text,
db.oid AS database_id,
db.datname AS database_name,
q.process_id,
0 AS aborted,
q.start_time,
q.end_time,
q.user_id,
q.label
FROM (
SELECT
q.userid AS user_id,
q.pid AS process_id,
q.xid,
q.starttime AS start_time,
MAX(q.endtime) AS end_time,
MIN(q.label) AS "label",
(LISTAGG(q.text, '') WITHIN GROUP (ORDER BY q.sequence)) AS query_text,
RANK() OVER(PARTITION BY q.userid, q.pid, q.xid ORDER BY q.starttime) AS query_part_rank
FROM pg_catalog.stl_ddltext AS q
CROSS JOIN parameters AS p
WHERE TRUE
AND DATE(q.starttime) = p.day_start
AND EXTRACT('hour' FROM q.starttime) BETWEEN p.hour_min AND p.hour_max
-- LISTAGG raises an error when total length >= 64K
AND q.sequence < (65535 / 200)
GROUP BY q.userid, q.pid, q.xid, q.starttime
) AS q
CROSS JOIN pg_catalog.pg_database AS db
WHERE db.datname = CURRENT_DATABASE()
),
merged AS (
SELECT * FROM read_query
UNION DISTINCT
SELECT * FROM ddl_query
)
SELECT
q.*,
u.usename AS user_name
FROM merged AS q
JOIN pg_catalog.pg_user AS u ON u.usesysid = q.user_id
- Views DDL
SELECT
CURRENT_DATABASE() AS database_name,
n.nspname AS schema_name,
c.relname AS view_name,
CASE
WHEN c.relnatts > 0 THEN 'CREATE OR REPLACE VIEW ' + QUOTE_IDENT(n.nspname) + '.' + QUOTE_IDENT(c.relname) + ' AS\n' + COALESCE(pg_get_viewdef(c.oid, TRUE), '')
ELSE COALESCE(pg_get_viewdef(c.oid, TRUE), '')
END AS view_definition
FROM
pg_catalog.pg_class AS c
INNER JOIN
pg_catalog.pg_namespace AS n
ON c.relnamespace = n.oid
WHERE
TRUE
AND relkind = 'v'
AND n.nspname NOT IN ('information_schema', 'pg_catalog');
References
See these AWS topics for additional detail: