Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
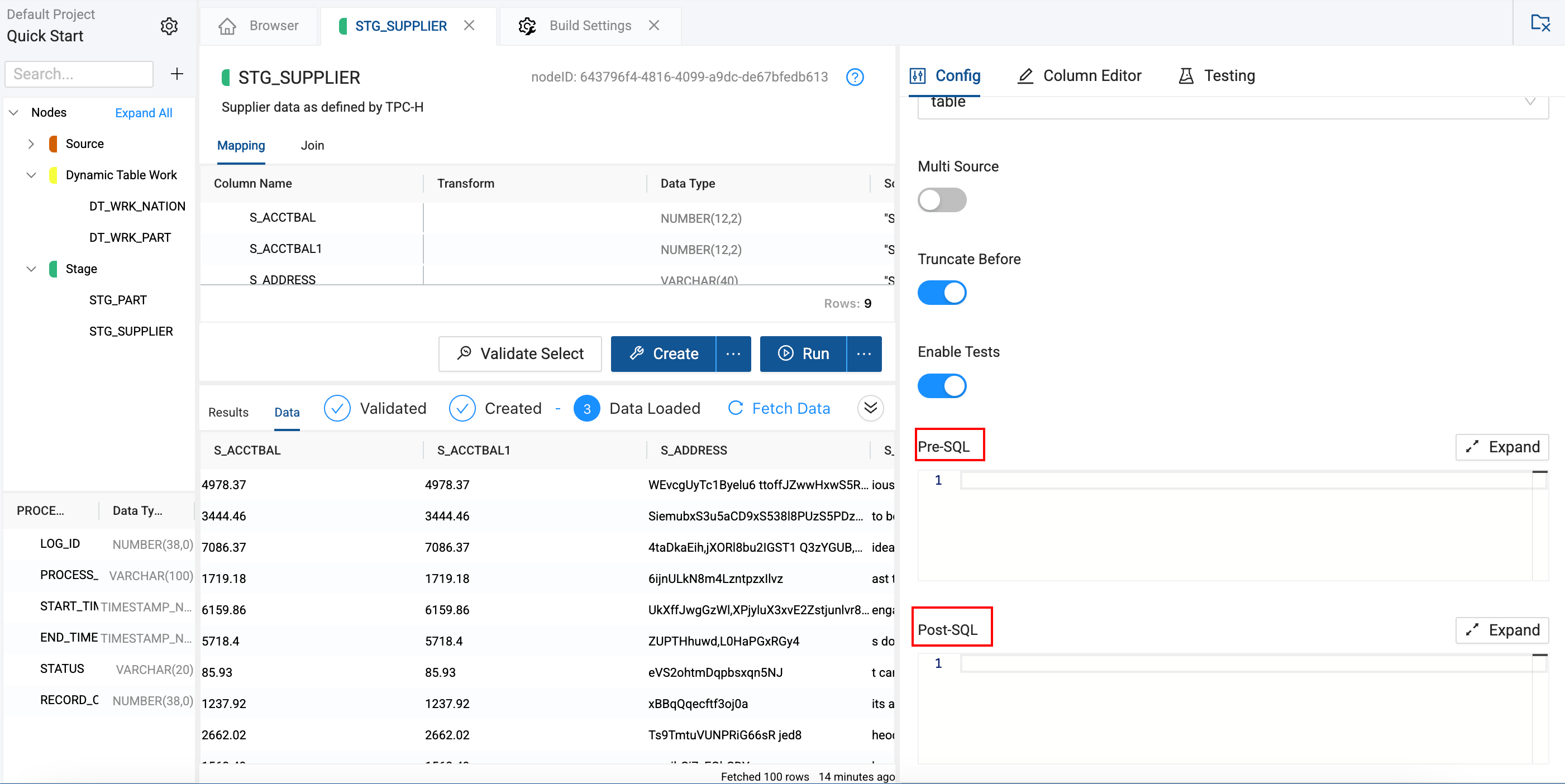
Pre-SQL and Post-SQL
Some Nodes come with Pre-SQL and Post-SQL boxes which allow you to run SQL either before or after the main operations.
- Pre‑SQL box lets you specify SQL that runs before the Node’s primary DML/DDL operations.
- Post‑SQL box executes after the primary operation has completed.
This guide has examples showing how pre-sql and post-sql can be used.
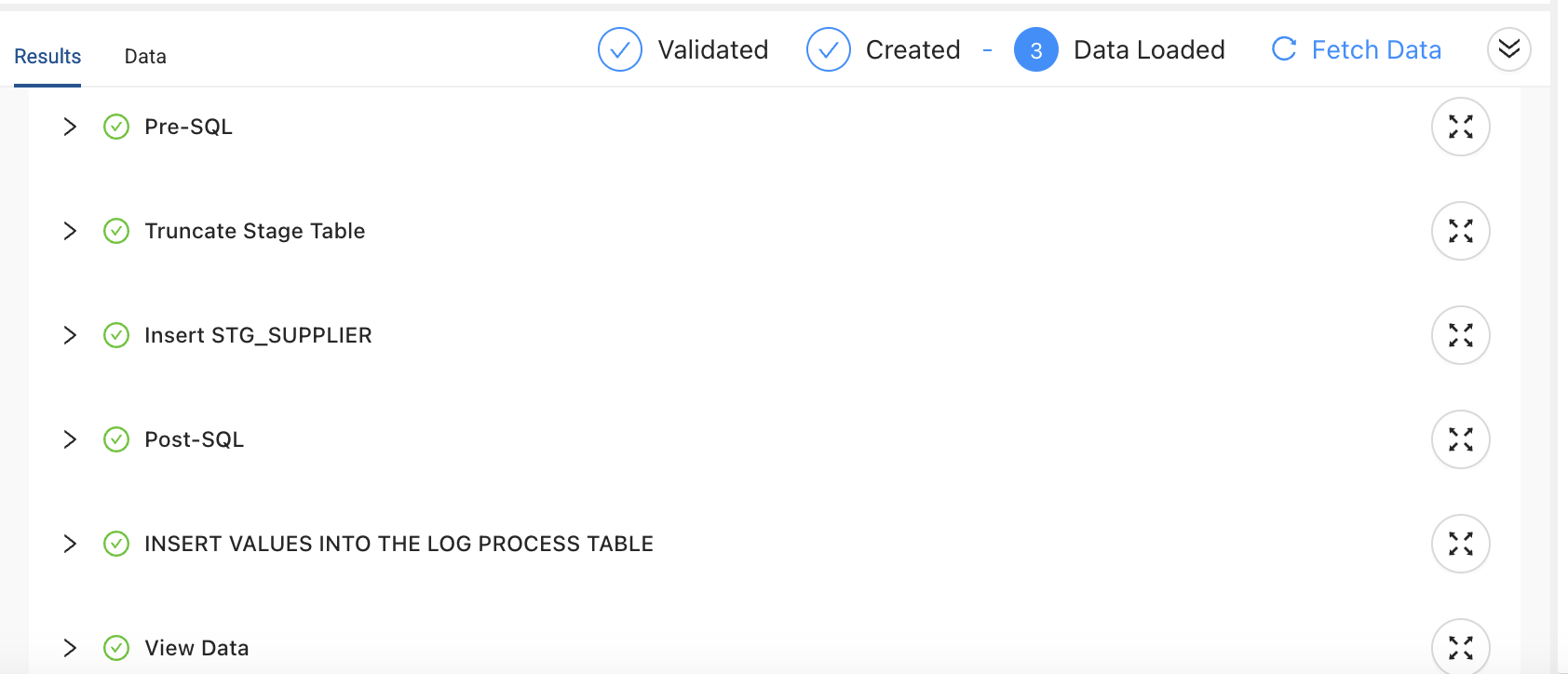
Creating a Process Log and Masking Sensitive Data
Before processing supplier data from a CSV file, you want to create a log table to capture processing details. After loading data into STG_SUPPLIER, you update sensitive fields for suppliers with high account balances.
How this works:
- The Pre‑SQL step sets up a logging table to track processing details.
- The Post‑SQL step masks part of the address for high‑value suppliers.
- There must a stage in between SQL statements to run multiple.
ref_no_link('WORK', 'STG_SUPPLIER')ensures the correct fully qualified table name is used without linking Nodes in the DAG.
- Snowflake
- Databricks
- BigQuery
--Create a process log table.
CREATE TABLE DOCUMENTATION.LOGS.PROCESS_LOG_NINE (
-- DATABASE.SCHEMA.TABLE
LOG_ID NUMBER IDENTITY(1,1),
PROCESS_NAME VARCHAR(100),
START_TIME TIMESTAMP,
END_TIME TIMESTAMP,
STATUS VARCHAR(20),
RECORD_COUNT NUMBER
);
--Create a process log table.
CREATE TABLE DOCUMENTATION.LOGS.PROCESS_LOG_NINE (
LOG_ID BIGINT GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1),
PROCESS_NAME STRING,
START_TIME TIMESTAMP,
END_TIME TIMESTAMP,
STATUS STRING,
RECORD_COUNT BIGINT
);
--Create a process log table.
CREATE TABLE DOCUMENTATION.LOGS.PROCESS_LOG_NINE (
LOG_ID INT64 GENERATED BY DEFAULT AS IDENTITY,
PROCESS_NAME STRING,
START_TIME TIMESTAMP,
END_TIME TIMESTAMP,
STATUS STRING,
RECORD_COUNT INT64
);
See Identity and Surrogate Keys in Coalesce for how Coalesce generates identity columns on each platform.
- Snowflake
- Databricks
- BigQuery
UPDATE {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
SET "S_ADDRESS" = SUBSTRING("S_ADDRESS", 1, 10) || '***'
WHERE "S_ACCTBAL" > 5000;
UPDATE {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
SET `S_ADDRESS` = SUBSTR(`S_ADDRESS`, 1, 10) || '***'
WHERE `S_ACCTBAL` > 5000;
UPDATE {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
SET `S_ADDRESS` = CONCAT(SUBSTR(`S_ADDRESS`, 1, 10), '***')
WHERE `S_ACCTBAL` > 5000;
Some UPDATE Post-SQL patterns fail against views or certain partitioned tables. Run the Post-SQL step in your Project before you schedule it in a Job.
- Snowflake
- Databricks
- BigQuery
{{stage('INSERT VALUES INTO THE LOG PROCESS TABLE')}}
INSERT INTO DOCUMENTATION.LOGS.PROCESS_LOG_NINE (PROCESS_NAME, START_TIME, END_TIME, STATUS, RECORD_COUNT)
VALUES (
'Supplier Load Process',
CURRENT_TIMESTAMP,
CURRENT_TIMESTAMP,
'SUCCESS',
(SELECT COUNT(*) FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }})
);
{{stage('INSERT VALUES INTO THE LOG PROCESS TABLE')}}
INSERT INTO DOCUMENTATION.LOGS.PROCESS_LOG_NINE (PROCESS_NAME, START_TIME, END_TIME, STATUS, RECORD_COUNT)
VALUES (
'Supplier Load Process',
CURRENT_TIMESTAMP,
CURRENT_TIMESTAMP,
'SUCCESS',
(SELECT COUNT(*) FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }})
);
{{stage('INSERT VALUES INTO THE LOG PROCESS TABLE')}}
INSERT INTO DOCUMENTATION.LOGS.PROCESS_LOG_NINE (PROCESS_NAME, START_TIME, END_TIME, STATUS, RECORD_COUNT)
VALUES (
'Supplier Load Process',
CURRENT_TIMESTAMP,
CURRENT_TIMESTAMP,
'SUCCESS',
(SELECT COUNT(*) FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }})
);
Back Up and Audit Supplier Data
You need to back up the existing data for auditing purposes. After the load, you want to identify any duplicate supplier IDs and log these duplicates for further review.
How it works:
- The Pre‑SQL creates or replaces a backup table by copying the current contents of
STG_SUPPLIERfrom theWORKmapping. This backup ensures you have a snapshot of the data before any transformations occur. - The Post‑SQL checks for an audit log table, then audits the stage data for duplicate supplier IDs. Any duplicates found are inserted into the audit log for further investigation.
{{ ref_no_link('WORK', 'STG_SUPPLIER') }}makes sure the correct reference to theSTG_SUPPLIERtable without creating dependencies.
CREATE OR REPLACE TABLE DOCUMENTATION.DEV.SUPPLIER_BACKUP AS
SELECT * FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }};
- Snowflake
- Databricks
- BigQuery
-- Create the audit log table if it doesn't exist
CREATE TABLE IF NOT EXISTS DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (
S_SUPPKEY NUMBER,
S_NAME VARCHAR(100),
DUPLICATE_COUNT NUMBER,
AUDIT_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
{{stage('Log Duplicates')}}
-- Log duplicates found in the stage table
INSERT INTO DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (S_SUPPKEY, S_NAME, DUPLICATE_COUNT)
SELECT "S_SUPPKEY", "S_NAME", COUNT(*) AS DUPLICATE_COUNT
FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
GROUP BY "S_SUPPKEY", "S_NAME"
HAVING COUNT(*) > 1;
-- Create the audit log table if it doesn't exist
CREATE TABLE IF NOT EXISTS DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (
S_SUPPKEY BIGINT,
S_NAME STRING,
DUPLICATE_COUNT BIGINT,
AUDIT_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
{{stage('Log Duplicates')}}
-- Log duplicates found in the stage table
INSERT INTO DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (S_SUPPKEY, S_NAME, DUPLICATE_COUNT)
SELECT `S_SUPPKEY`, `S_NAME`, COUNT(*) AS DUPLICATE_COUNT
FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
GROUP BY `S_SUPPKEY`, `S_NAME`
HAVING COUNT(*) > 1;
-- Create the audit log table if it doesn't exist
CREATE TABLE IF NOT EXISTS DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (
S_SUPPKEY INT64,
S_NAME STRING,
DUPLICATE_COUNT INT64,
AUDIT_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
{{stage('Log Duplicates')}}
-- Log duplicates found in the stage table
INSERT INTO DOCUMENTATION.DEV.SUPPLIER_AUDIT_ONE (S_SUPPKEY, S_NAME, DUPLICATE_COUNT)
SELECT `S_SUPPKEY`, `S_NAME`, COUNT(*) AS DUPLICATE_COUNT
FROM {{ ref_no_link('WORK', 'STG_SUPPLIER') }}
GROUP BY `S_SUPPKEY`, `S_NAME`
HAVING COUNT(*) > 1;
Run Multiple SQL Statements
You can either run them as separate stages or as one stage. If you try to run multiple SQL statements without this, you'll get an error: Actual statement count 2 did not match the desired statement count 1.
SELECT * FROM <table>
{{stage('SOME STAGE INFO')}}
INSERT INTO <table>
- Snowflake
- Databricks
- BigQuery
BEGIN
SELECT * FROM <table>;
INSERT INTO <table>;
END;
BEGIN
SELECT * FROM <table>;
INSERT INTO <table>;
END;
BEGIN
SELECT * FROM <table>;
INSERT INTO <table>;
END;