Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Data Quality Testing
Coalesce provides built-in testing capabilities to assess the quality of your data.
Data quality tests are crucial for identifying issues with data, such as missing values, incorrect data types, outliers, and violations of business rules. Testing data quality within Coalesce offers the advantage of validating transformed data against required standards before loading it into the target system. Integration of data testing into the existing data pipeline workflow enables early issue detection and ensures consistency across different data sources and transformations.
Coalesce's Approach to End-to-End Testing
Coalesce addresses this challenge by providing built-in Node testing capabilities . These tests can be at the Column level or at the Nodelevel.
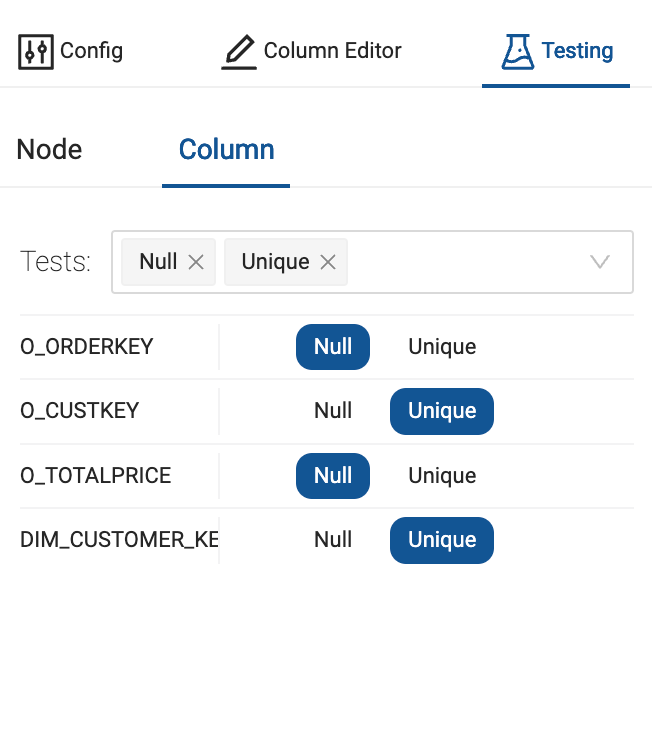
At the column level, you can test individual columns for uniqueness and null values. By clicking on the Testing icon after selecting a node. There, you can indicate the tests to run and which columns to run the tests on.
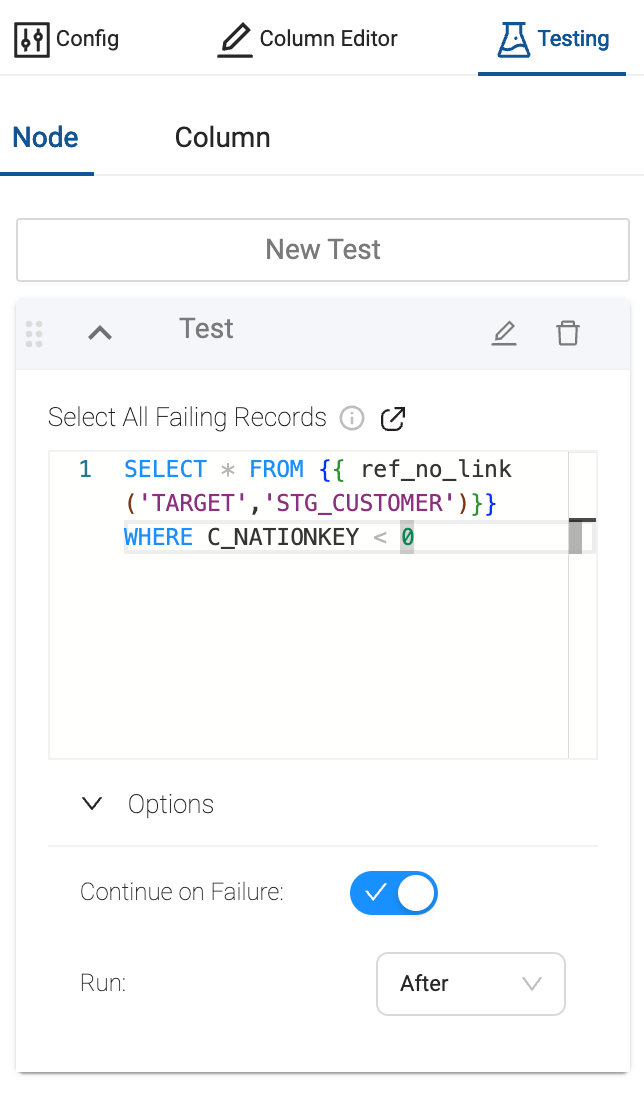
You can write custom tests at the node level with SQL queries. If the query returns a result, the test is considered failed. You can also leverage the Options to indicate whether or not to halt the pipeline execution upon test failure and whether to run the tests before or after the node refresh.
Leveraging Environments for Comprehensive Testing
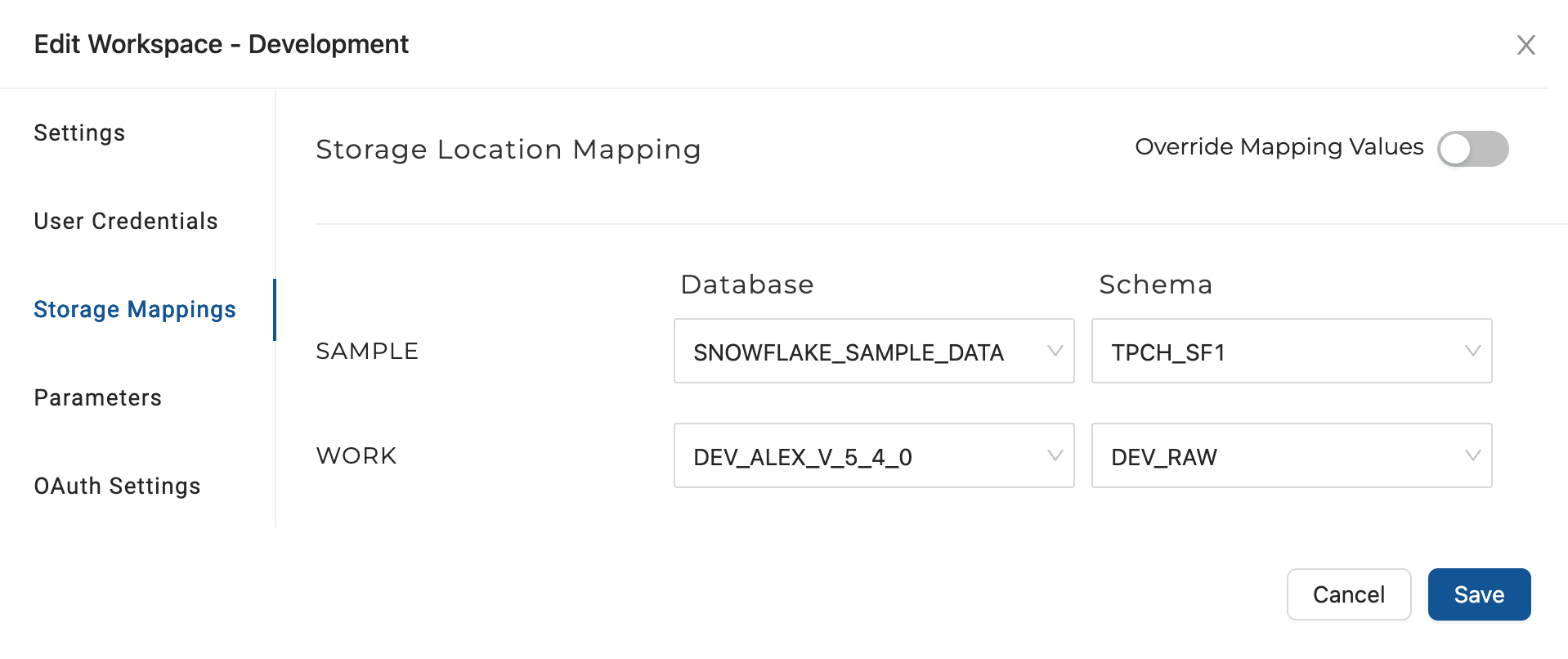
Environmentsin Coalesce offer another powerful framework for end-to-end testing. Users can deploy data pipelines to different sets of databases and schemas, allowing them to simulate scenarios using 'dummy' data. By configuring different target Storage Location mappings for the desired output database and schema, users can thoroughly test their pipelines.
For example, you can designate an environment known as “DEV” that contains database objects that match edge cases for certain data (data with duplicates, null valued records, etc.) and once pipelines are deployed, can trigger certain tests/checks written into the nodes upon Refresh. Only once all “tests” pass in the QA environment, are the pipelines eligible to be deployed to production.
This approach enables you to point the pipeline to simulated data, ensuring thorough testing, and publish the outputs to a designated test dataset. It provides a flexible and robust solution for users aiming to verify their pipelines comprehensively.
What To Test For
- Missing or null values: Test for columns that should not have null or missing values based on your business requirements.
- Data types: Ensure that columns have the correct data types (strings, integers, dates) to avoid downstream issues.
- Uniqueness: Test for columns or combinations of columns that should have unique values.
- Value ranges: Validate that numerical or date columns fall within expected ranges based on your business rules.
- Referential integrity: Test for foreign key relationships between tables to ensure data consistency.
- Custom business rules: Implement tests that enforce specific business rules or data quality requirements specific to your organization.