Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
How to use GROUP BY
GROUP BY is completed in Coalesce by adding your GROUP BY clause after the FROM statement, as well as after any other precursor statements like JOINs and/or a WHERE clause, in the Join tab of your Node Editor of the Node where you will complete the GROUP BY.
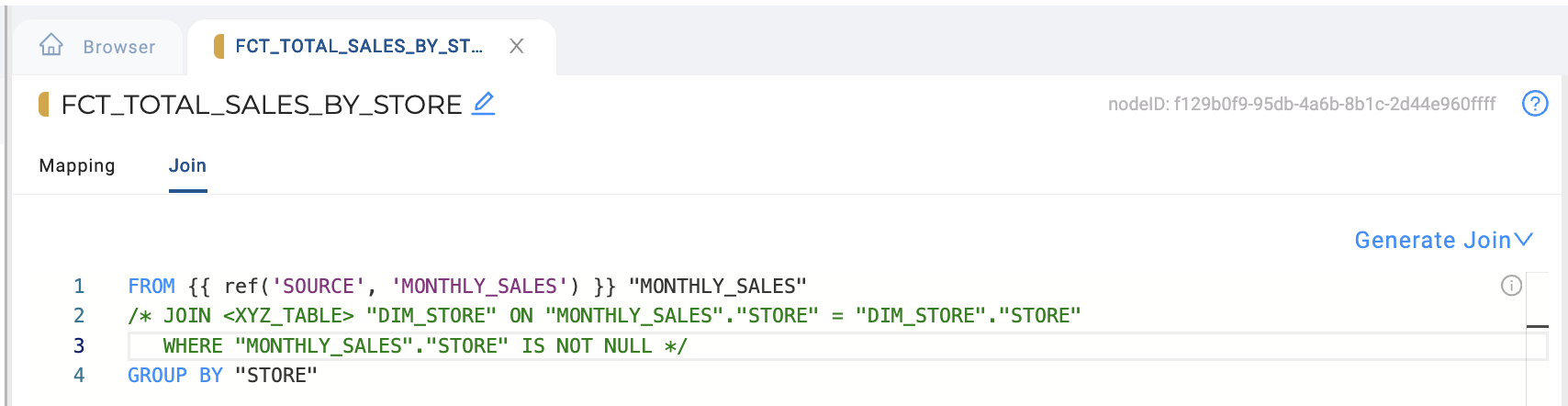
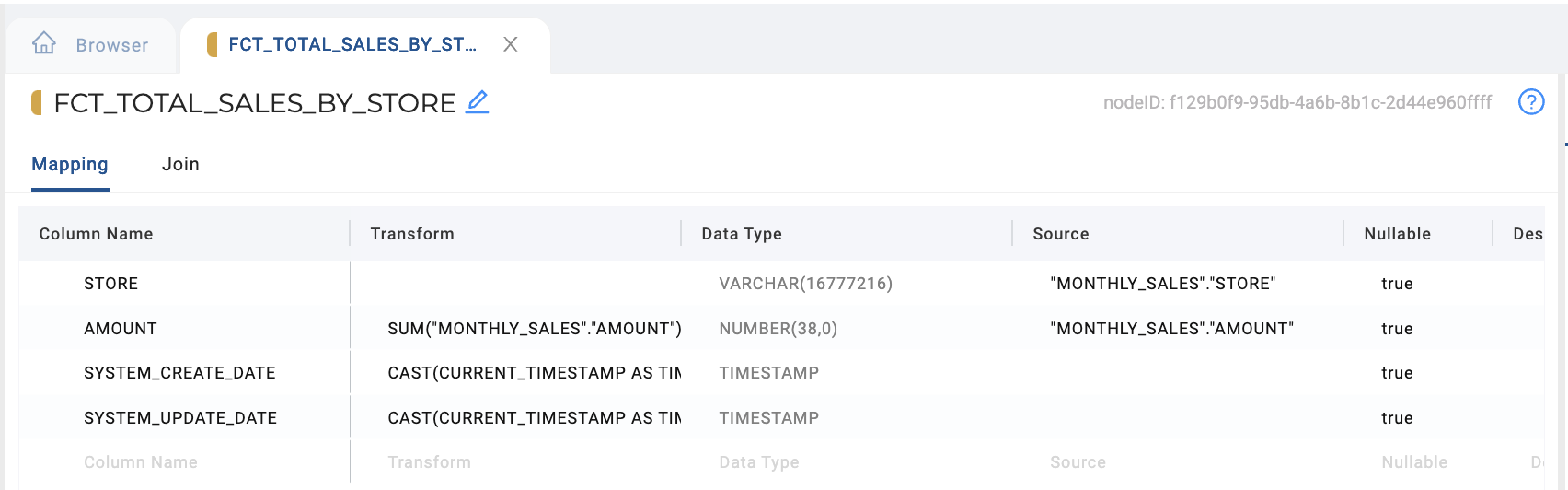
You will have to ensure your columns are configured correctly in your Mapping tab in terms of aggregation Transforms on column you wish to aggregate and Sources for columns you wish to GROUP BY in order for the GROUP BY to execute successfully.
GROUP BY Detailed Example
To provide a more detailed example, let's say you have a raw table of monthly sales amounts by store and month that you'd like to transform and load into a Fact Table of sales amounts by store in total. But rather than loading the actual store value into your Fact Table, you want to pull in the corresponding dimension key for each store from your Store Dimension, so you also need to join to your Store Dimension while completing this transform and load.

-
Add a Fact Node from your main source (
MONTHLY_SALES).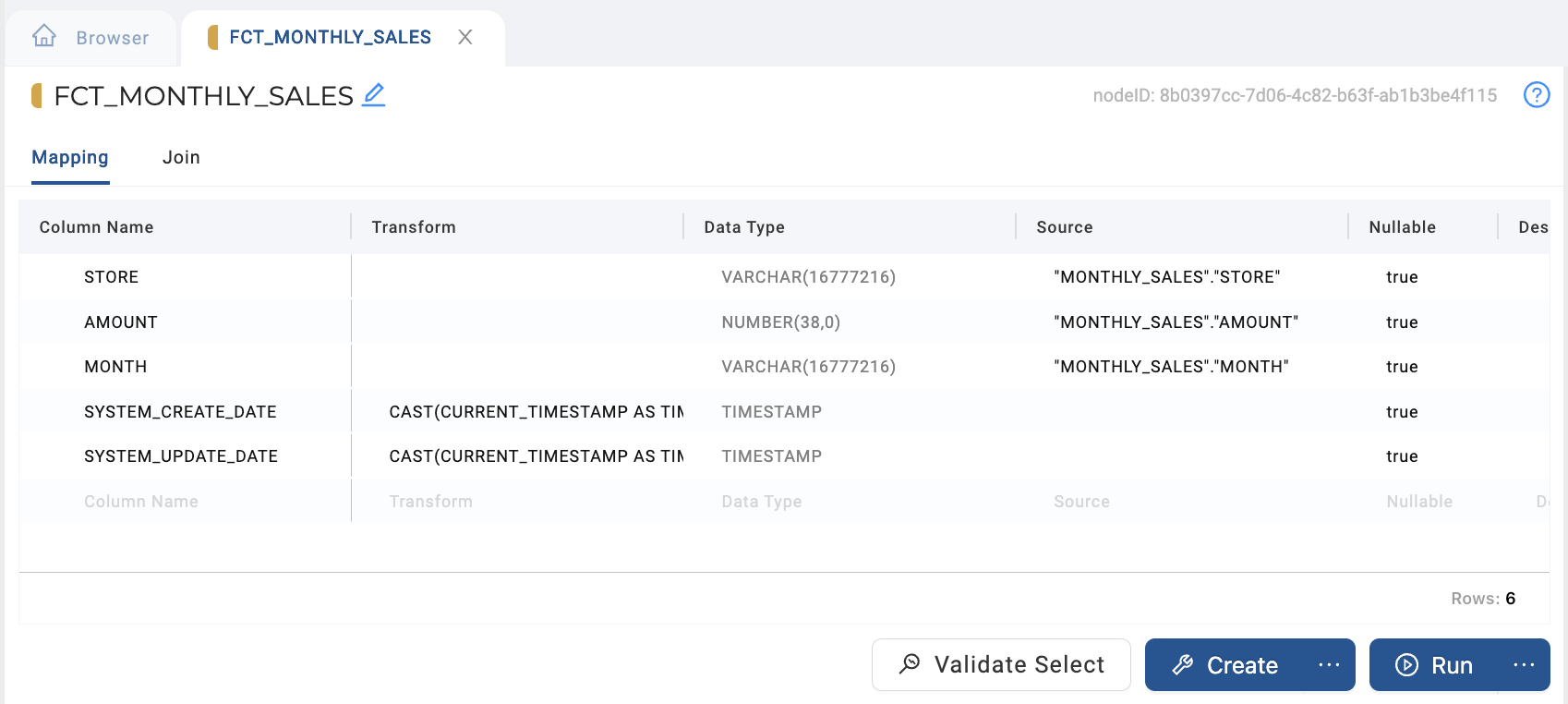
-
Remove the columns you don't want to include in your new Fact (
STOREin its raw form andMONTH) and configure your aggregations on your columns.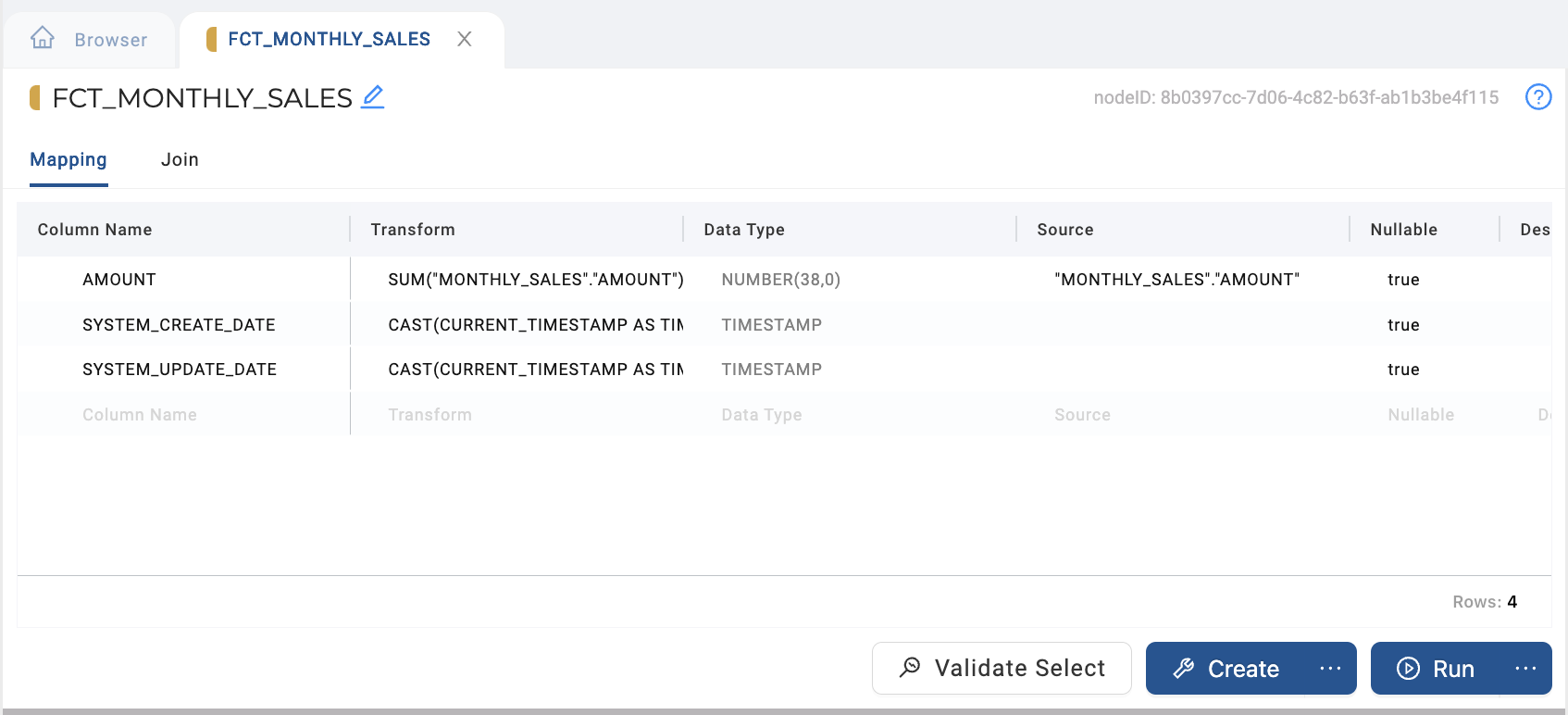
-
Map in the key from your Store Dimension (
DIM_STORE).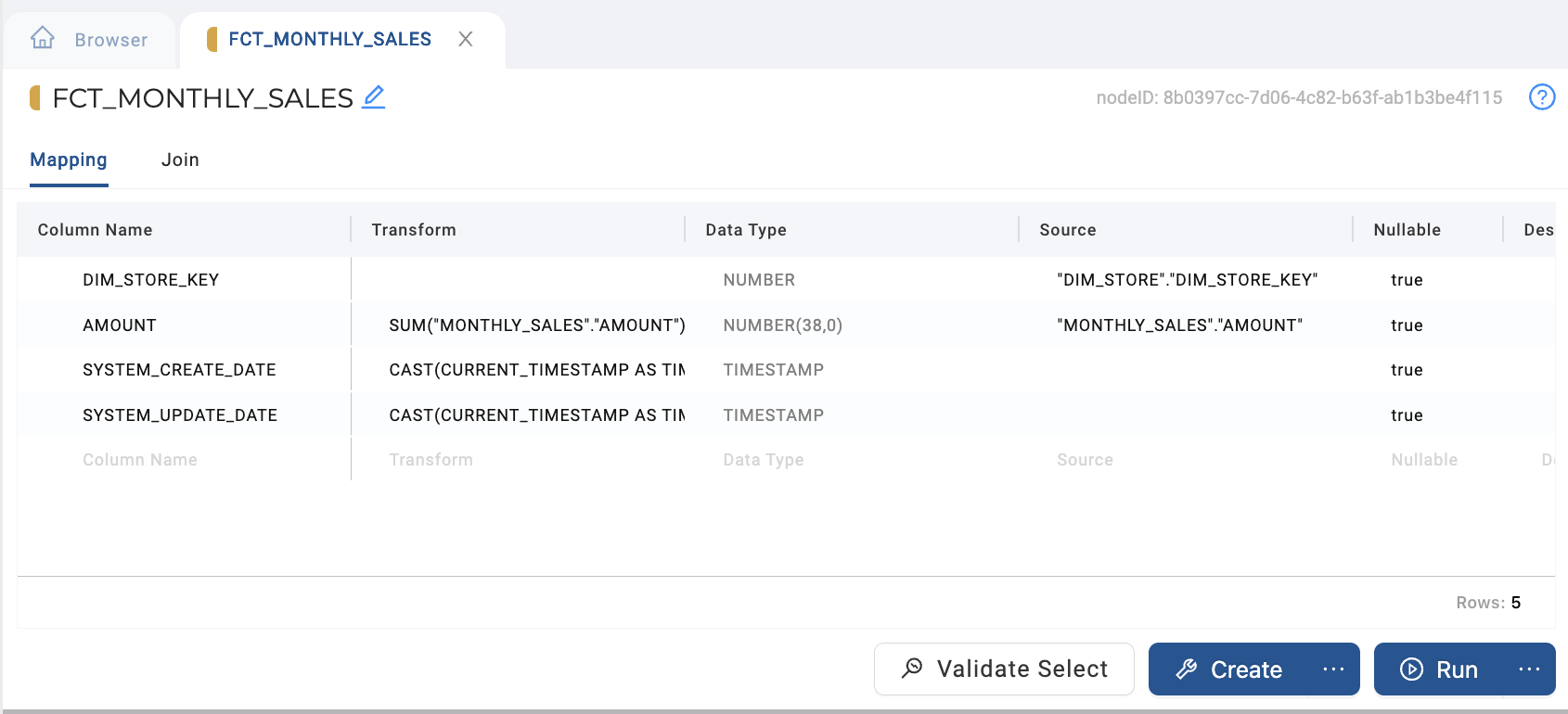
-
Configure your join between your main source (MONTHLY_SALES) and your Store Dimension (
DIM_STORE).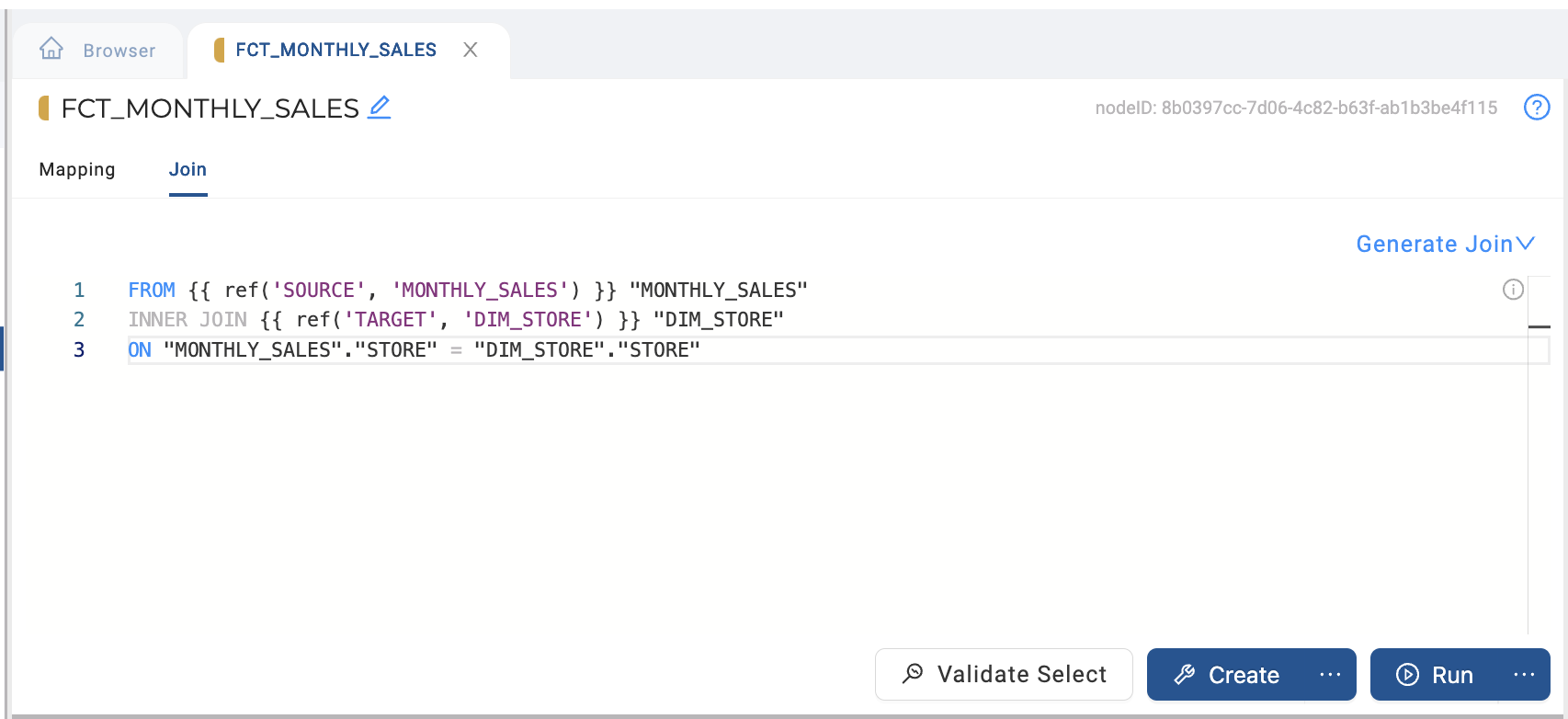
-
Add a GROUP BY clause after your join on your Store Dimension key (
DIM_STORE.DIM_STORE_KEY).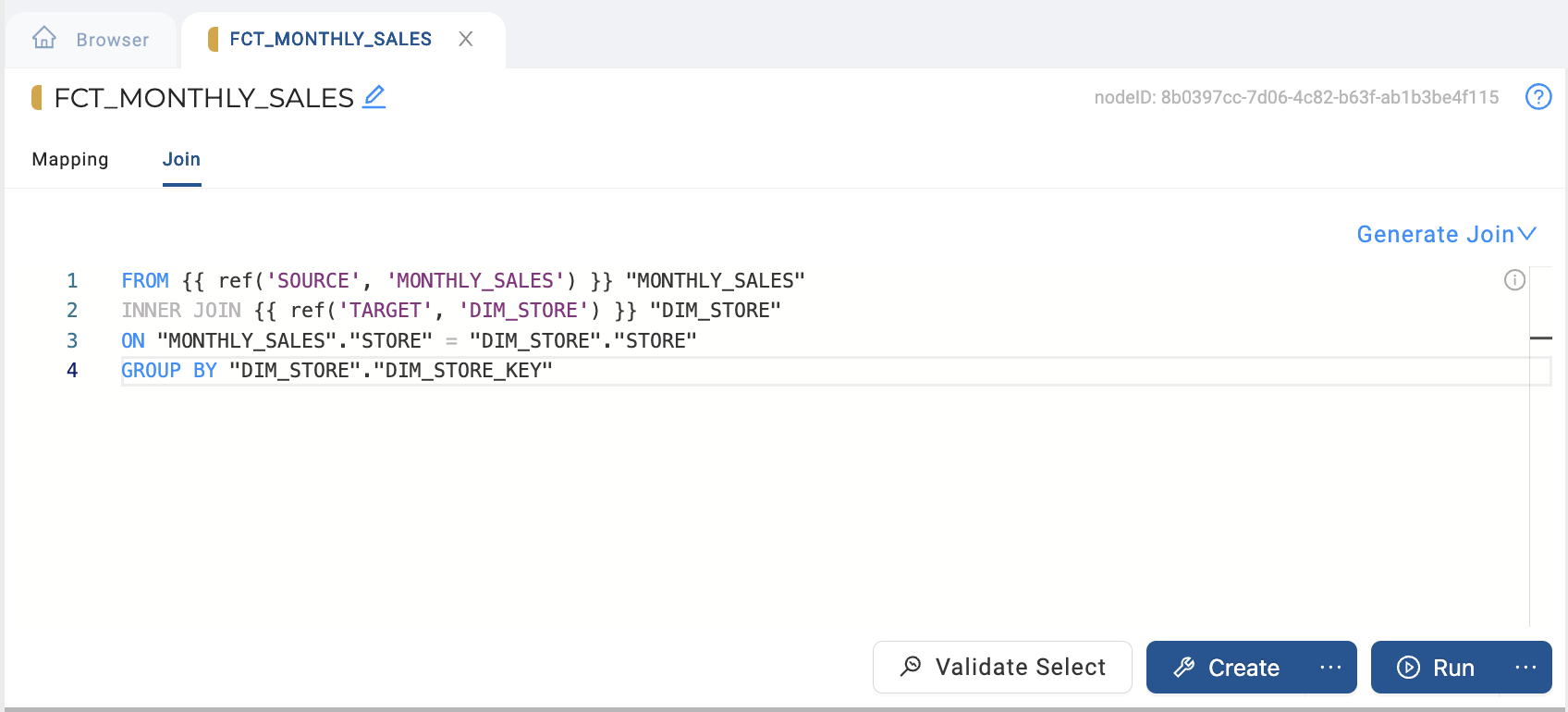
-
Within the Node Editor:
- Validate Select.
- Validate Create.
- Create.
- Validate Run.
- Fetch data, and view grouped results.
