Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Migrate a CTE to Coalesce
Coalesce believes pipelines, rather than Common Table Expressions (or CTEs), are the ideal approach for data transformations. We've included a high level overview of each approach below, and our article CTEs vs Pipelines for Complex Data Processing details our philosophy on this approach as well as provides an introductory walkthrough of the approach. In this article, we dig deeper into the approach with a step by step example detailing how to migrate a CTE to a pipeline in Coalesce.
Common Table Expressions (CTEs)
Common table expressions, or CTEs, are used to embed complexity in several SQL blocks pulled together into a single SELECT or DML operation. Within the context of data transformation, by processing data this way, developers are able to consolidate logic within the context of a single SQL file. This means there are less files to manage overall, but managing the logic contained within those files becomes increasingly more complex as data transformation projects grow.
Pipelines
Pipelines allow for each logical process in a typical CTE to be broken into their own SQL blocks, or what Coalesce calls Nodes. In addition to reducing complexity, the pipeline approach provides lineage at the object and column level that is not possible with CTEs.
Build with a Pipeline Approach in Coalesce Video
Coalesce believes in a pipeline approach for data modeling and transformation. However, if you are migrating from a code first solution that uses CTEs to Coalesce, it is not always obvious where to start. In the following video, we show how you can take a CTE and what migrating that into Coalesce looks like.
Migrating a CTE to Coalesce
We'll now walk you through the process of migrating a CTE to Coalesce. Here is the CTE code that we will be migrating to Coalesce:
with stg_location as (
select location_id,
placekey,
location,
upper(city) as city,
region,
iso_country_code,
country
from FROSTBYTE_TASTY_BYTES.RAW_POS.LOCATION
where location_id is not null
and location_id != 0
),
stg_customer_loyalty as (
select customer_id,
first_name,
last_name,
upper(city) as city,
country,
left(postal_code, 5) as postal_code,
e_mail,
phone_number,
coalesce(e_mail, phone_number) as contact_info
from FROSTBYTE_TASTY_BYTES.RAW_CUSTOMER.CUSTOMER_LOYALTY
where customer_id is not null
and (e_mail is not null or phone_number is not null)
),
stg_truck as (
select truck_id,
menu_type_id,
primary_city,
year,
upper(make) as make,
upper(model) as model,
ev_flag,
franchise_id,
truck_opening_date
from FROSTBYTE_TASTY_BYTES.RAW_POS.TRUCK
where truck_id is not null and TRUCK_OPENING_DATE::date < '2024-01-01'
),
stg_order_header as (
select order_id,
truck_id,
order_id || truck_id as primary_key,
location_id,
customer_id,
discount_id,
shift_id,
shift_start_time,
shift_end_time,
order_channel,
order_ts,
order_ts::date as order_date,
served_ts,
order_currency,
order_amount,
order_tax_amount,
order_discount_amount,
order_total
from FROSTBYTE_TASTY_BYTES.RAW_POS.ORDER_HEADER
where order_id is not null
and truck_id is not null
and order_total >= 0
),
stg_order_totals as (
select order_id,
order_currency,
sum(ORDER_AMOUNT) as total_order_amount,
sum(ORDER_TAX_AMOUNT) as total_tax_amount,
sum(ORDER_DISCOUNT_AMOUNT) as total_discount_amount,
sum(order_total) as total_order_value
from stg_order_header
group by order_id,
order_currency
),
orders_cleaned as (
select soh.order_id,
soh.truck_id,
primary_key,
soh.location_id,
soh.customer_id,
discount_id,
order_ts,
order_date,
served_ts,
sot.order_currency,
total_order_amount,
total_tax_amount,
total_discount_amount,
total_order_value,
sl.city,
location,
make as truck_make,
model as truck_model,
first_name as cust_first_name,
last_name as cust_last_name,
contact_info,
row_number() over (partition by primary_key order by order_ts) as dupe_count
from stg_order_header as soh
inner join stg_location as sl
on soh.LOCATION_ID = sl.LOCATION_ID
inner join stg_truck as st
on soh.TRUCK_ID = st.TRUCK_ID
inner join stg_customer_loyalty as scl
on soh.CUSTOMER_ID = scl.CUSTOMER_ID
inner join stg_order_totals as sot
on soh.order_id = sot.order_id
where order_date is not null
and contact_info is not null
qualify dupe_count = 1
)
select *
from orders_cleaned
Identify Your Data Sources
When migrating a CTE to Coalesce, the first thing you should do is identify all of the data sources that will need to be brought into your pipeline.
It is possible that a CTE will have a dependency that will need to be created first, before you can migrate the CTE. You should create any dependencies first within Coalesce.

Once you have identified your data sources, you can create them within your Coalesce workspace. In the example CTE used here, each of the sources is a raw data table, so these tables can be added in as sources into the Coalesce workspace.
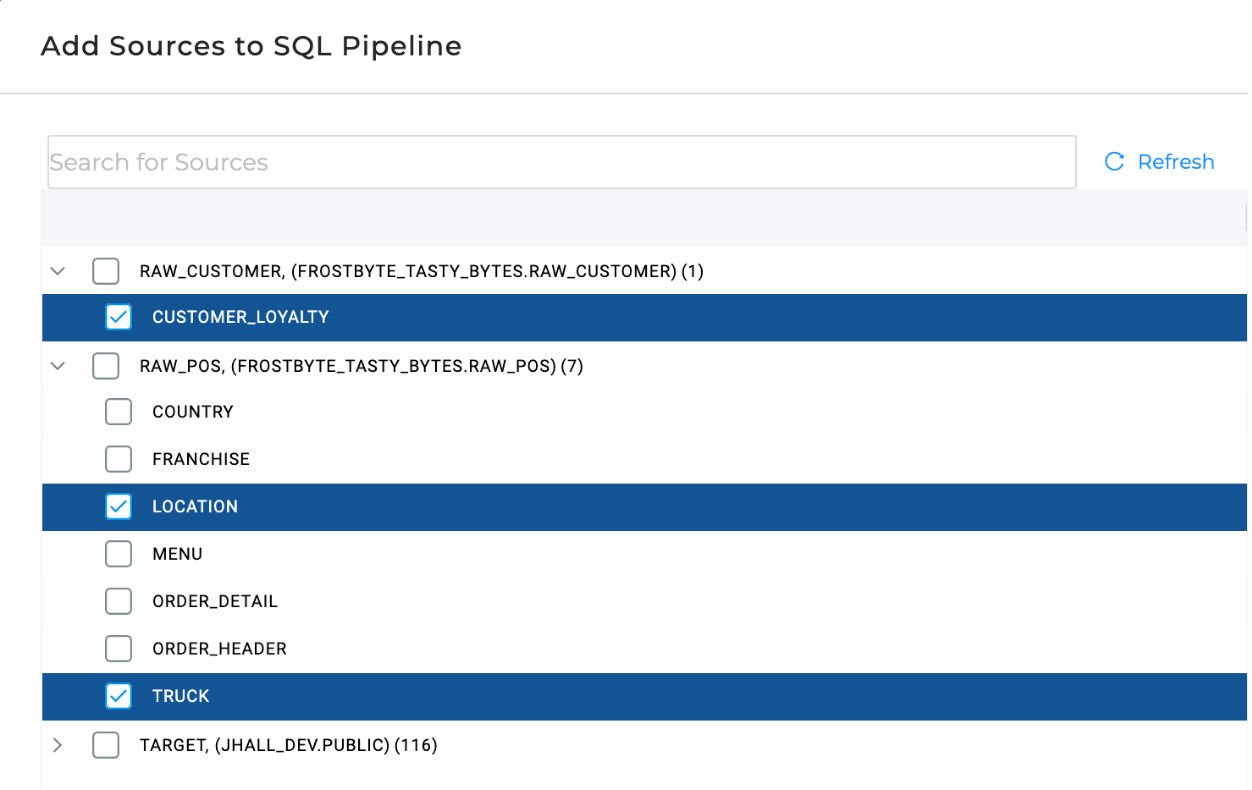
In the case of a CTE having a dependency that is not a raw data source, you would create or use existing nodes within your pipeline, to support the logic of the CTE.
Migrate Your Logic in Sequential Order
Once you have data sources added to your pipeline, you can begin migrating the logic from your CTE in the order in which the CTE is written (top to bottom). This will ensure that any dependencies created within the CTE are available to be processed as you complete your migration.
For example, in the image below, you can see the stg_order_totals CTE is dependent upon the stg_order_header CTE. If these were to be created out of sequential order, the stg_order_header CTE would not be available for the stg_order_totals CTE to reference.

Migrate Each CTE
Once you have identified the order in which you are migrating your CTEs, you can begin migrating each CTE into Coalesce. Let’s take a look at migrating the first CTE from our code.
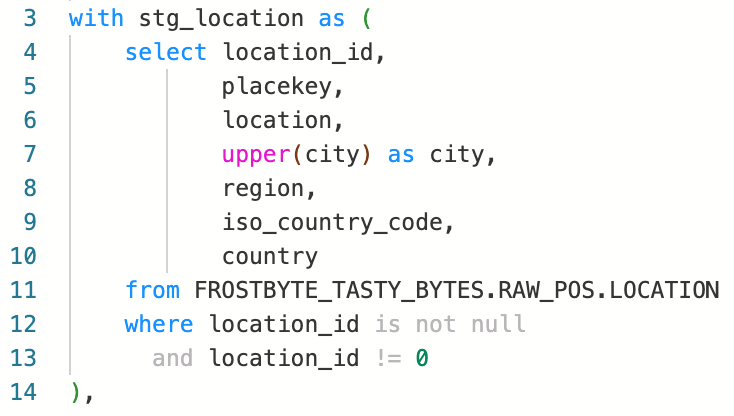
It can be helpful to think of each SELECT statement in a CTE as its own node in Coalesce. Although this will not always be the case, in most scenarios, a single CTE can be represented by a single node. Since this CTE is processing some raw data and applying some transformations, we can use a stage node to reflect these transformations in Coalesce.
Coalesce will automatically bring in all of the columns from the source table. From there, we can apply the UPPER function to the city column, within the Transform field of Coalesce.
There is a WHERE statement that has two filter conditions applied. We can apply the same logic within the JOIN tab of Coalesce.

With that, we’ve just migrated the stg_location CTE into Coalesce.
Migrating a CTE Complex Example
Let’s walk through one more example that’s a little more complex.

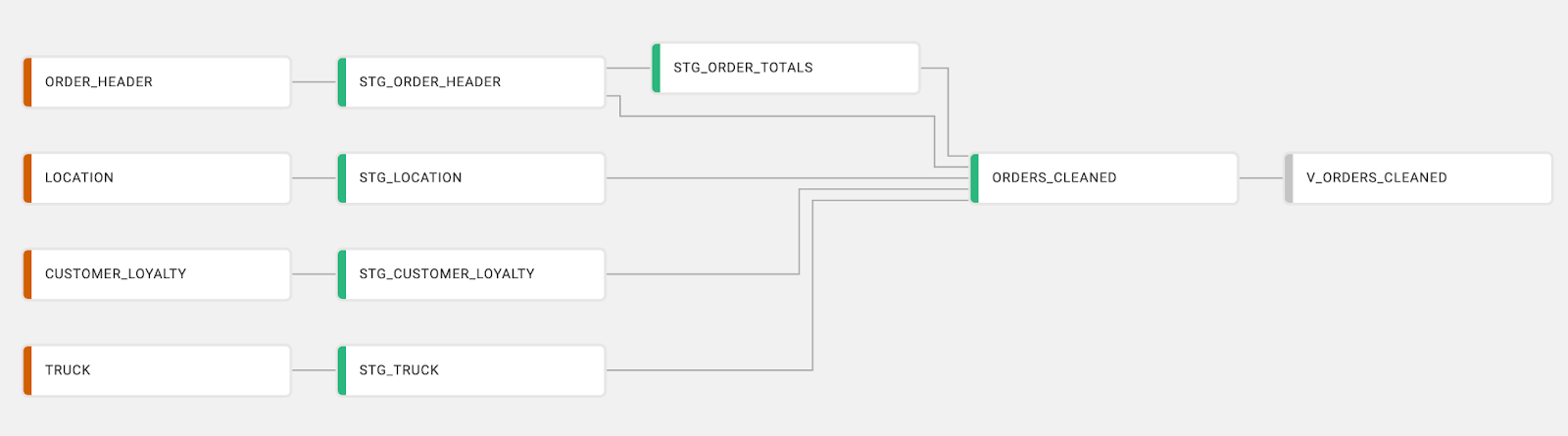
The order_cleaned CTE is joining multiple other CTEs together, adding a column, and applying some filters.
First, we need to ensure that the upstream dependencies have been created.
stg_order_headerstg_locationstg_truckstg_customer_loyaltystg_order_totals
For this example, let’s assume you’ve already migrated the rest of these nodes:
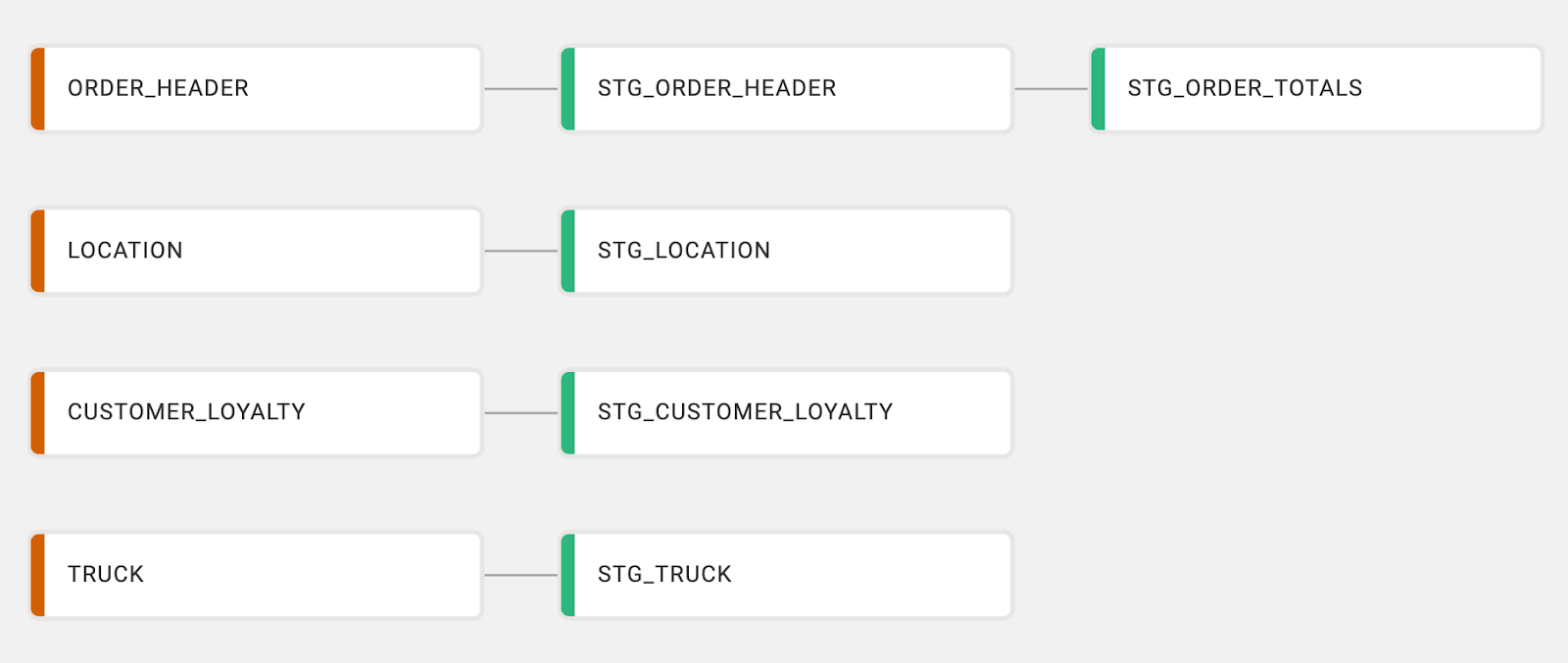
With these nodes available, we can create a new node that joins all of these nodes together: just like in the CTE. You can hold down shift and select all of the nodes together, right click on any node, and select Join Nodes > Stage.
Coalesce will automatically generate the join syntax in the Join tab of the new node.
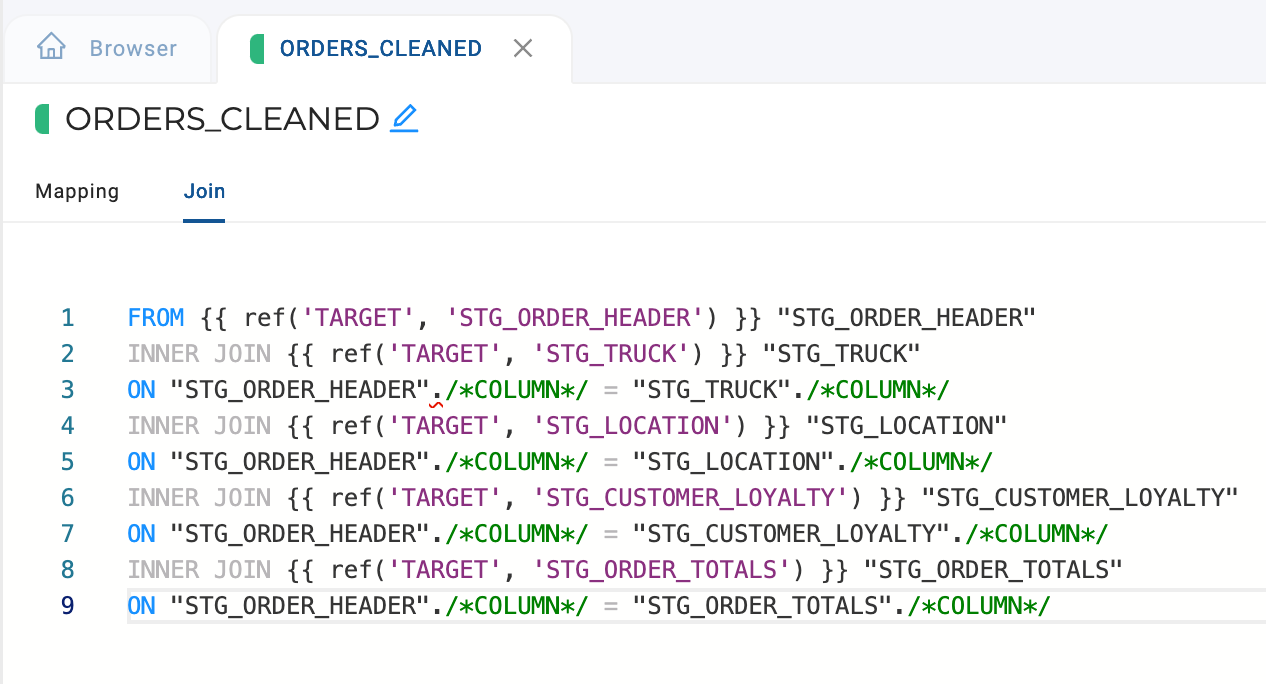
From here, all you need to do is replace the /*COLUMN*/ with the actual column reference for the join.
With the join complete, we can go back to the mapping grid and delete the columns we don’t need, so they can match the same columns from the CTE. Additionally, we can add the window function called DUPE_COUNT by double clicking on the Column Name area of the mapping grid.
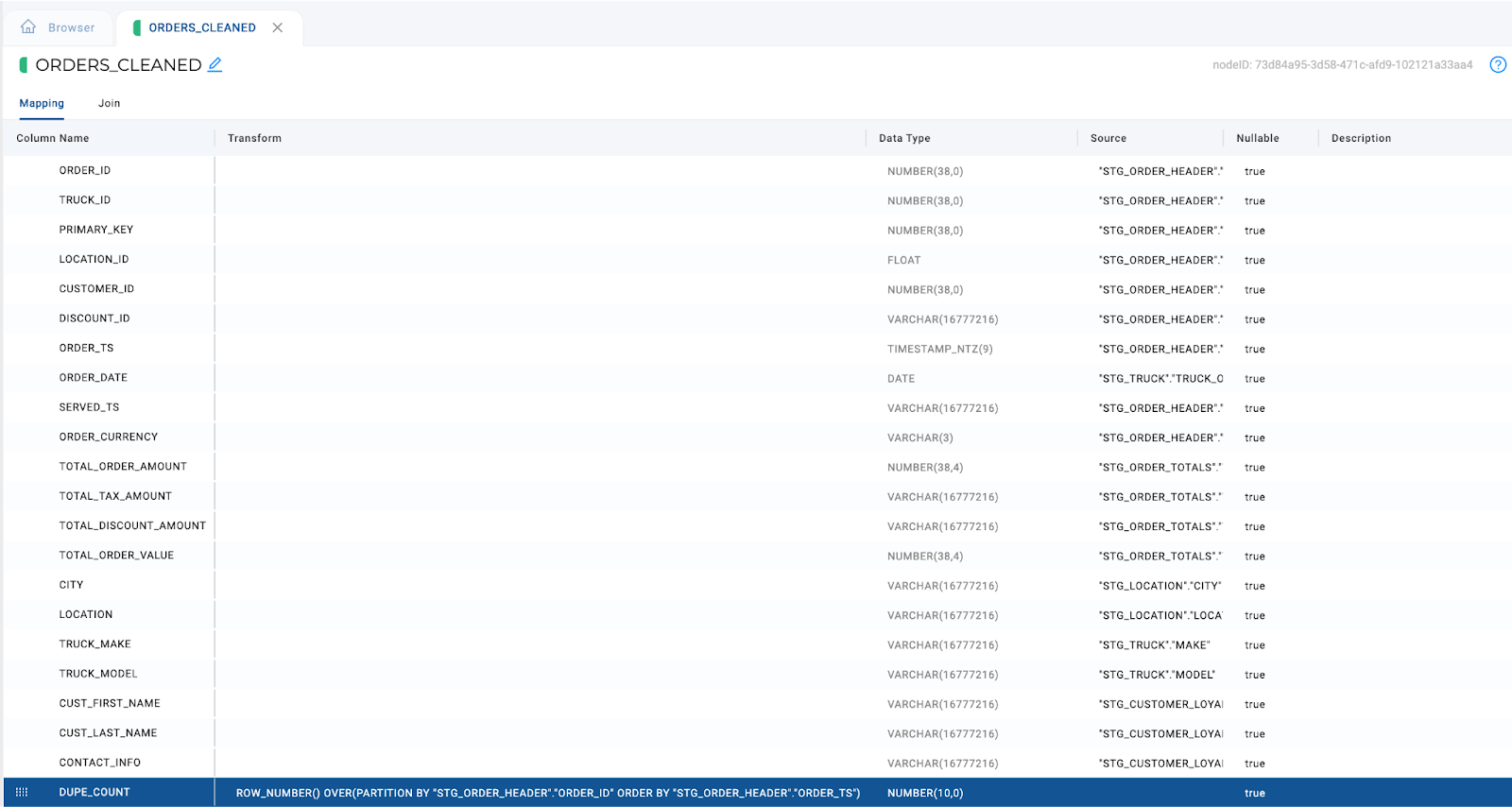
With the window function added, we can apply the filters to the node.
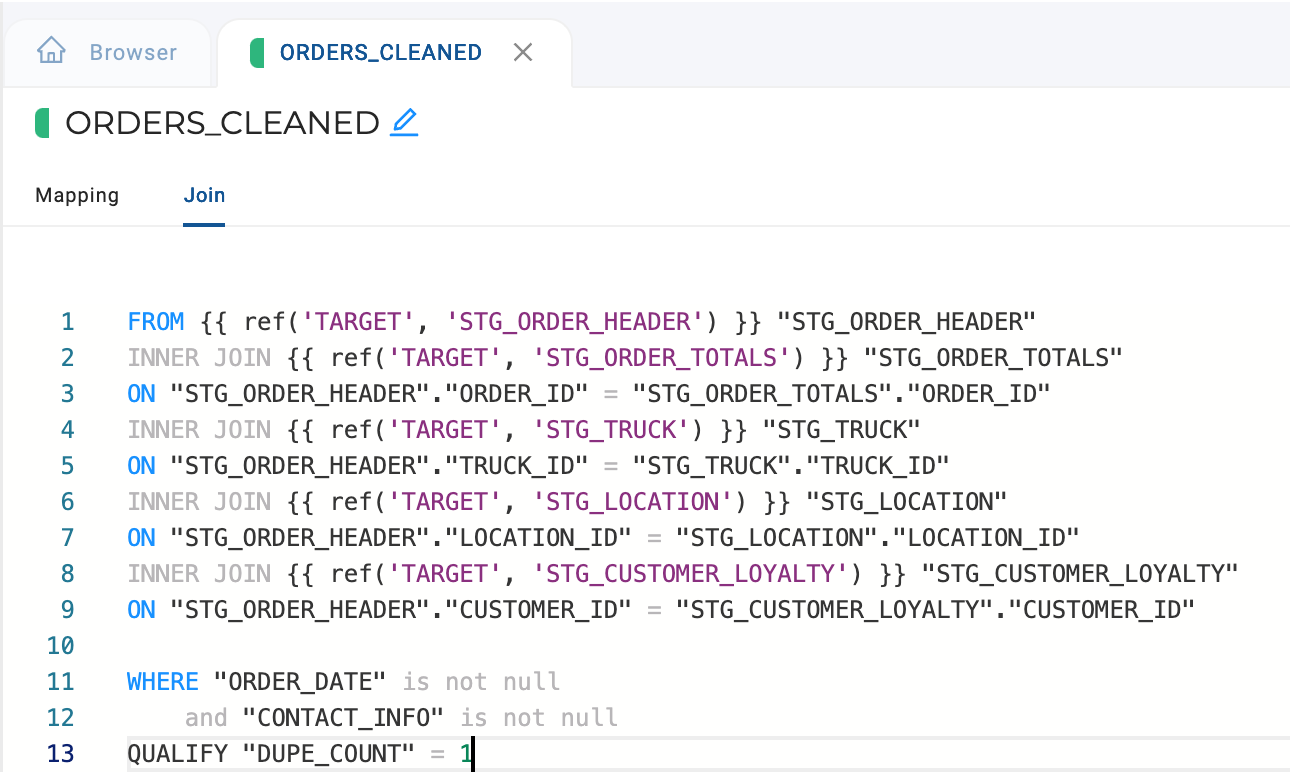
With the filters added, we have successfully migrated a complex CTE into Coalesce, while taking advantage of several of the features of Coalesce that allow you to streamline development.
Once each CTE has been migrated to Coalesce, your pipeline using the code above, would look something like this:
Migrate Intentionally
Migrating CTEs to Coalesce is a streamlined process that allows you to gain additional transparency, adaptability, and scalability. When migrating CTEs, it is important to follow a migration process to ensure a CTE can be fully created in Coalesce:
- Identify data sources
- Identify any dependencies
- Migrate CTEs in sequential order
By following this process, migrations can be quickly and easily completed, allowing you to gain all the advantages of building your data transformations in a pipeline pattern. For questions about migrating CTEs, you can open a support request.