Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
The Node Editor
The Node Editor can be opened by double-clicking on any node from the sidebar, from within the graph or subgraphs. For Subgraph layout, naming, and how Subgraphs relate to the main graph, see Using Subgraphs to Build Your Pipeline.
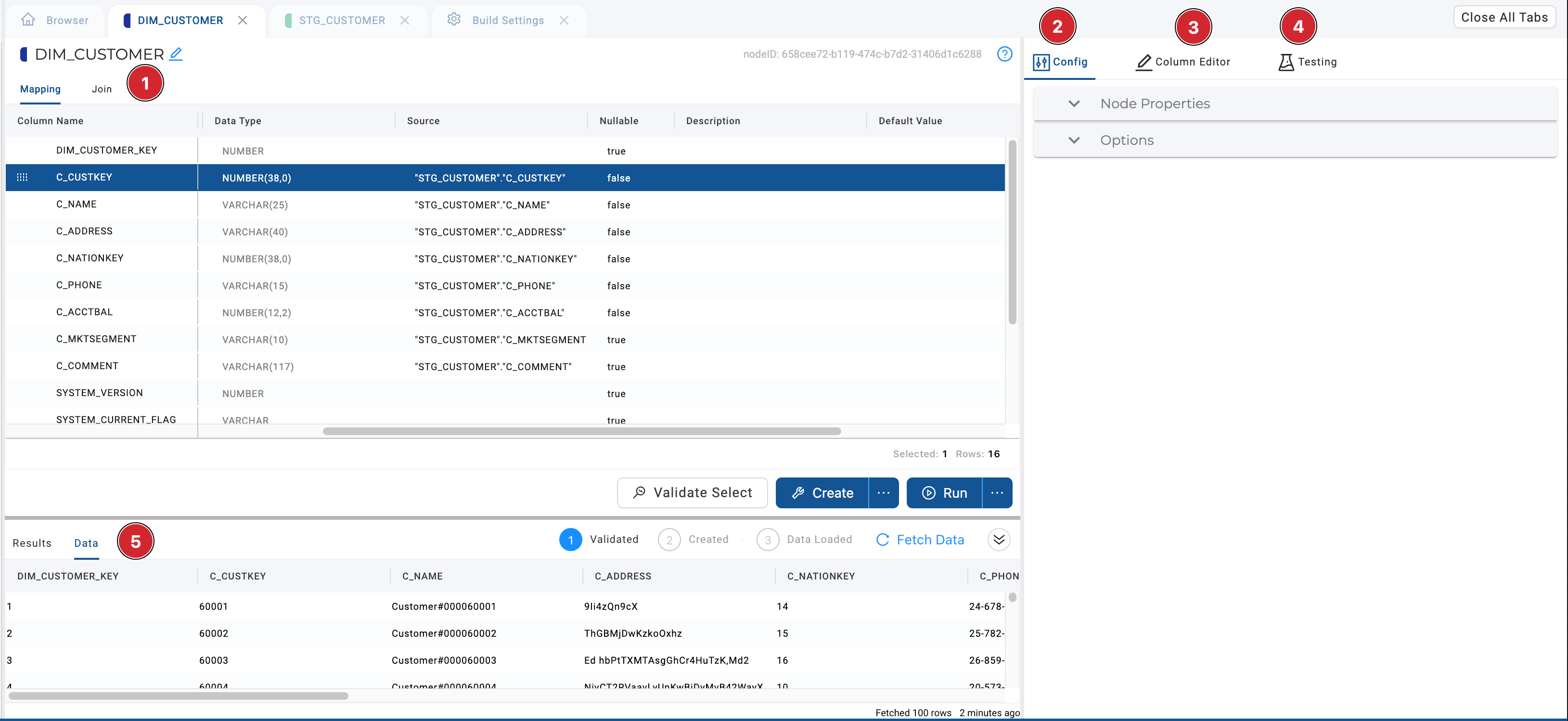
- The Mapping Grid and Join Tab is where you'll be able to transform, edit, and parse your data. These two areas combined define not only the current node structure but what source will be used to populate the current node and the mapping of that data to each column. Some of the things you can do include:
- General transformations
- Bulk Data Editing
- Testing
- JSON and XML transformations
- Edit Node and column data. Use Coalesce's AI
 to generate your Node and column descriptions.
to generate your Node and column descriptions.
Organization administrators can go to Org Settings > Preferences and turn the features on or off for the whole organizations. These features are not enabled by default, reach out to your Coalesce account manager to sign up.
- Config
- Node Properties - Review and edit your nodes Storage Location, Type, and other information.
- Options - The options available will depend on the node type. To see potential options, review Node Config Options .
- Column Editor - Select a column to add transforms. You can select multiple columns to bulk edit the data.
- Testing- Test your node to assess the data quality.
- Results and Data Pane - This section provides the user with feedback as to exactly what SQL was queried and the ability to preview the data results within the application.
Node Actions
A node has several different execution modes that can be executed on a single node. They are in the Results and Data Pane.
Validate SQL
Validate SQL constructs a simple SELECT statement combining transformations and source mapping metadata with the JOIN string defined in the join tab. The SELECT statement is wrapped with EXPLAIN USING TEXT. EXPLAIN compiles the SQL statement, but does not execute it. This removes any complexity of the underlying template and only validates the user inputted transformations and joins.
Create
Create renders and executes all SQL stages of the create template defined in the Node Type definition.
Validate Create
Validate Create renders and validates all SQL stages of the create template defined in the Node Type definition. However, unlike Create each SQL stage is wrapped with EXPLAIN USING TEXT. EXPLAIN compiles the SQL statement, but does not execute it.
Run
Run renders and executes all SQL stages of the run template defined in the Node Type definition.
Validate Run
Validate Run renders and validates all SQL stages of the run template defined in the Node Type definition. However, unlike Run each SQL stage is wrapped with EXPLAIN USING TEXT. EXPLAIN compiles the SQL statement, but does not execute it.
Add Columns
Inherit From Nodes
Right-click in the graph or sidebar with one Node selected and choose Add Nodes, or multi-select Nodes and choose Join Nodes, then pick a Node type. For the Workspace sidebar, Add Sources, Create a New Node, and graph controls, see The Build Interface. To remove a Node and keep the warehouse aligned with Coalesce, use Delete Node as described in Tables Dropped Outside of Coalesce.
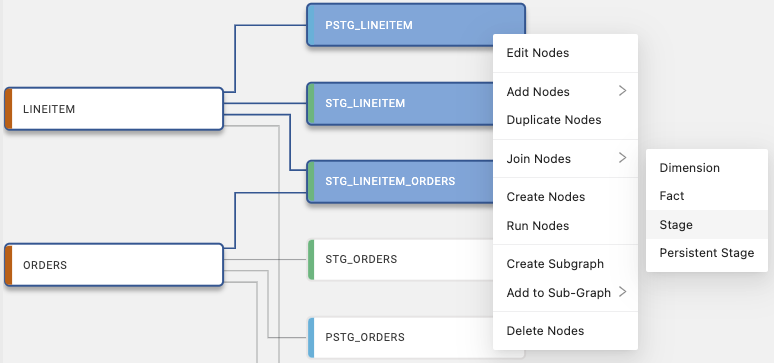
Manually Add Columns
- Drag in one or many nodes from sidebar Node Mapping View.
- Drag in individual columns from sidebar column preview pane.
Naming and Renaming a Node
Each data platform has it's own rules about naming Nodes.
| Data Platform | Spaces | Lowercase | Uppercase | Dashes | Underscore | Quotes |
|---|---|---|---|---|---|---|
| Snowflake | ✔ | ✔ | ✔ | ✔ | ||
| Databricks | ✔ | ✔ | ✔ |
When you rename a Node in Coalesce, it results in the creation of a new table in your data platform. You'll need to delete any tables directly. Renaming the Node directly in the data platform will result in a TABLE_OR_VIEW_NOT_FOUND in Coalesce.
After a rename, review Join tab SQL, transforms, and hard-coded names and update them to match the new Node and column names.
Change a Nodes Source
You can change a Node’s source if the upstream logic of your pipeline changes or if you need to point to a different table or Node for input. This is useful when refactoring your DAG or correcting data dependencies.
- Open the Node Editor.
- Select all the columns in the Node and then click Bulk Editor.
- Change the attribute to Source.
- Then choose either Node and Column or Node depending on your situation.
- Click Preview to make sure the changes are correct.
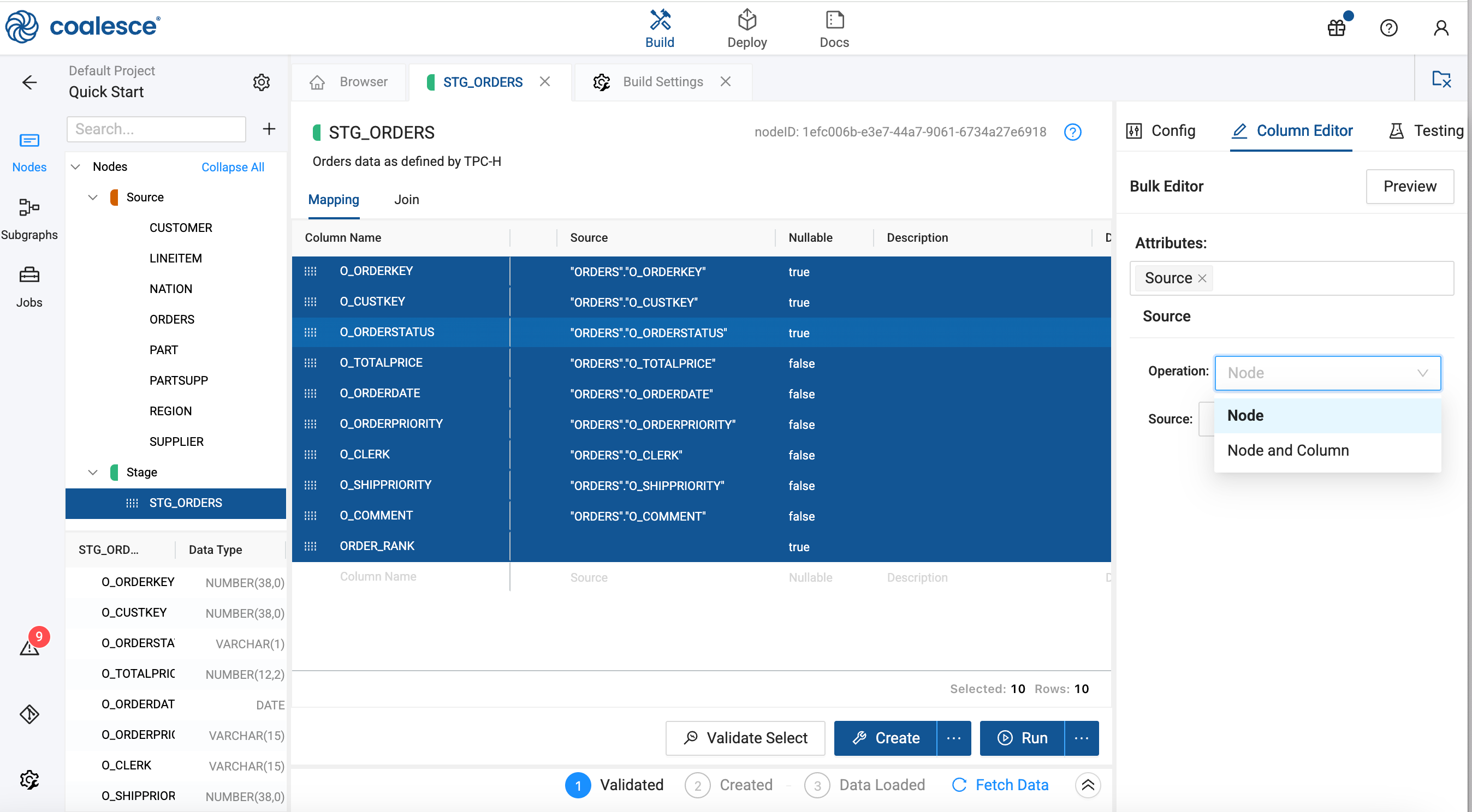
- If the new source has different columns or data types, your transformations may fail or produce incorrect results. Always check the Mapping View after changing the source.
- Changing a Node’s source can affect all downstream Nodes. You may need to update joins, filters, or transformations to align with the new data structure.
Managing Dependencies
Dependencies in the DAG come from creating downstream Nodes in the graph, from column Source settings in the Mapping grid, and from how other Nodes are referenced on the Join tab with ref macros. For the graph and sidebar workflows, see The Build Interface. For Join SQL and ref() usage, see the Join Tab and Ref Functions.
Mapping stores column-level links to specific upstream Node identities. Join SQL that uses ref() may still look correct after you replace or refactor a Source even when Mapping or lineage needs an update. After large upstream changes, review the Mapping grid and Bulk Editor Source settings, not only the Join Tab.
When Mapping, lineage, or Node names do not match what you expect after you change Sources or join logic, use this table.
| Issue | What to try |
|---|---|
| Join Tab looks fine after replacing a Source, but Mapping, lineage, or deploy warnings look wrong | Update column Source values in the Mapping grid or Bulk Editor so they reference the current upstream Node and columns. |
| Source bulk edit with Node seems to do nothing or preview looks broken | Node requires an exact column name match, including case, on the upstream Node. Use Node and Column when names differ. See Bulk Editing. |
| Graph or Subgraph omits an edge even though SQL references the table | Use ref_link() or ref_no_link() as in Ref Functions, or the patterns in Fix Un-Linked References in Sub-Graphs. |
| After a rename, Join tab SQL or transforms still reference old names | Manually update Join tab SQL and transforms to the new Node and column names. |