Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Getting Started with Node Type V2
This guide walks you through creating your first V2 Node: you create a V2 Node type, add its definition and Create and Run templates, add a Node to your pipeline and write SQL, configure behavior with annotations, then validate and deploy.
Prerequisites
You need the following:
- A Coalesce Workspace connected to Snowflake.
- At least one source Node in your pipeline to
SELECTfrom.
Step 1: Create a V2 Node Type
Before you can create a V2 Node, you need a V2 Node type. Node types are the templates that control how a Node deploys and runs, and they are shared across all Nodes of that type.
Go to Build Settings > Node Types and click the Create Node Type dropdown. Select the V2 option. This creates a Node type with version: 2 set. Give it a descriptive name, for example SQL Stage.
The Node type list includes a Version column so you can distinguish V1 and V2 types at a glance.
You can also duplicate an existing V2 Node type. The duplicate inherits version: 2 and the original's templates.
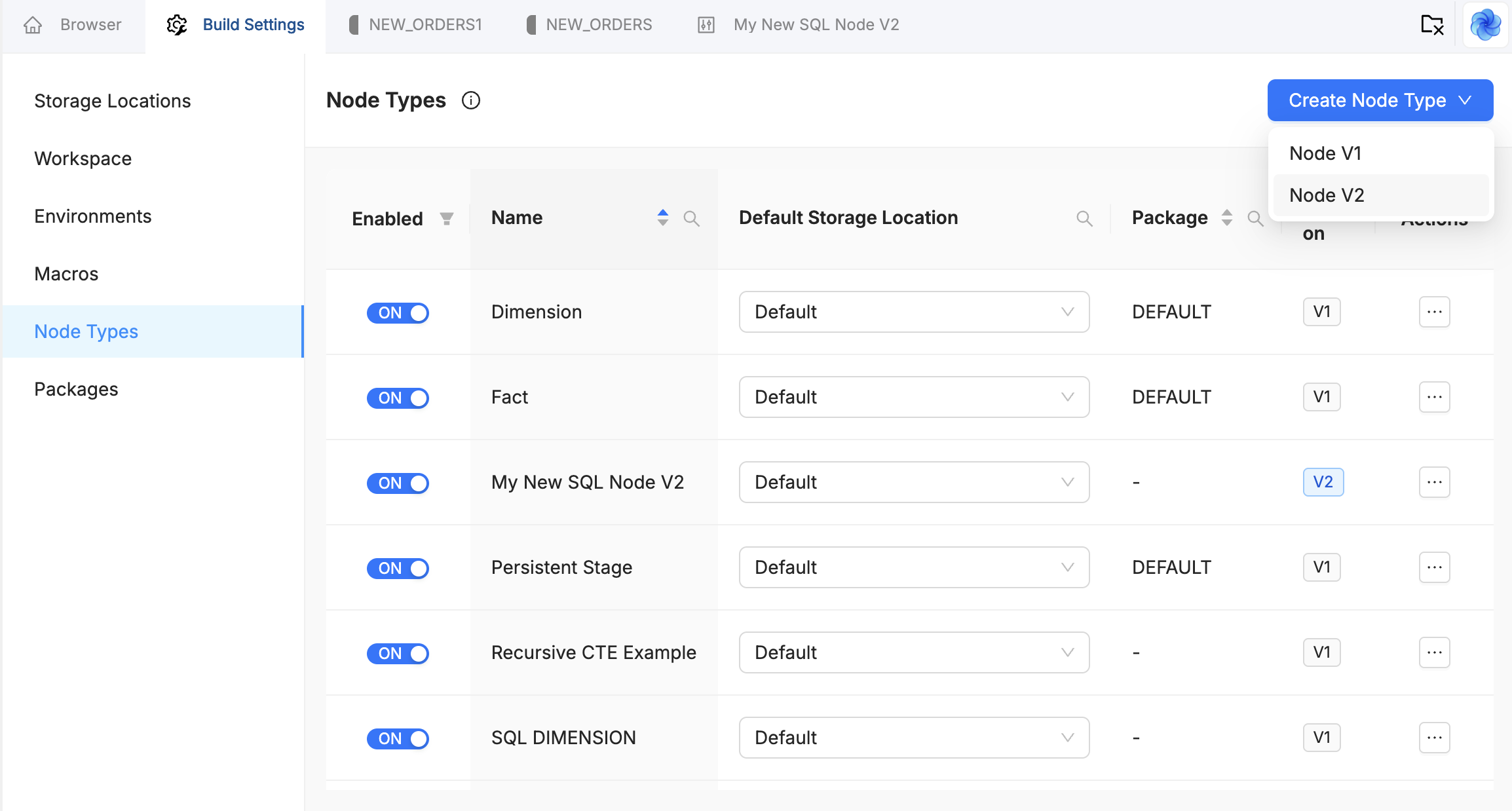
V2 Nodes are authored in SQL, but the Node type still needs a YAML definition and Create and Run templates. Declare each annotation you want to use, for example Truncate Before, Pre-SQL, or Multi Source Strategy, in the definition, handle it in templates, then set values in Node SQL or Options. Step 2 shows a full example.
Step 2: Add the Node Type Definition and Create and Run Templates
Open Build Settings > Node Types, select your V2 Node type, and configure the definition and templates before you rely on Nodes of that type in the graph. The YAML definition registers which annotations the type supports and which Options appear in the UI. The Create template emits DDL. The Run template emits load logic.
Each config item uses an attributeName that matches the annotation name in Node SQL, for example truncateBefore for @truncateBefore, or any custom name you define, such as myLoadMode for @myLoadMode. If you add an annotation in SQL but omit it from the definition, or omit the matching branch in a template, the option does not affect deployed SQL.
Node Type Definition in YAML
Paste or sync a definition like this so the Node type uses SQL input mode and CTE support. Your Workspace assigns the Node type id when you save in the Coalesce App.
capitalized: Copy of Stage
short: STG
plural: Stages
tagColor: '#2EB67D'
config:
- groupName: Options
items:
- type: materializationSelector
default: table
options:
- table
- view
isRequired: true
- type: multisourceToggle
enableIf: "{% if node.materializationType == 'table' %} true {% else %} false {% endif %}"
- type: overrideSQLToggle
enableIf: "{% if node.materializationType == 'view' %} true {% else %} false {% endif %}"
- displayName: Multi Source Strategy
attributeName: insertStrategy
type: dropdownSelector
default: INSERT
options:
- "INSERT"
- "UNION"
- "UNION ALL"
isRequired: true
enableIf: "{% if node.isMultisource %} true {% else %} false {% endif %}"
- displayName: Truncate Before
attributeName: truncateBefore
type: toggleButton
default: true
- displayName: Enable Tests
attributeName: testsEnabled
type: toggleButton
default: true
- displayName: Pre-SQL
attributeName: preSQL
type: textBox
syntax: sql
isRequired: false
- displayName: Post-SQL
attributeName: postSQL
type: textBox
syntax: sql
isRequired: false
Create Template
Create Template
{#
Copyright (c) 2026 Coalesce. All rights reserved.
This script and its associated documentation are confidential and proprietary to Coalesce.
Unauthorized reproduction, distribution, or disclosure of this material is strictly prohibited.
Coalesce permits you to copy and modify this script for the purposes of using with Coalesce but
does not permit copying or modification for any other purpose.
#}
{# == Node Type Name : SQL Insert == #}
{# == Node Type Description : This node creates work table or view == #}
{#---------------------------------------------------------------------------------------------#}
{%- if node.materializationType | lower in ['table', 'transient table'] %}
{{ stage('Create ' + node.materializationType ) }}
{# CreateSQL for Table #}
CREATE OR REPLACE {{ node.materializationType }} {{ ref_no_link(node.location.name, node.name) }}
(
{%- for col in columns %}
{%- set nullParams = col.nullable.parameters | default([]) %}
{%- set defaultValueParams = col.defaultValue.parameters | default([]) %}
{%- set descriptionParams = col.description.parameters | default([]) %}
"{{ col.name }}" {{ col.dataType }}
{%- if nullParams and (nullParams[0] in ['false', false]) %} NOT NULL {%- endif %}
{%- if defaultValueParams and defaultValueParams[0] is not none %} DEFAULT {{ get_default(col.dataType, defaultValueParams[0]) }} {%- endif %}
{%- if descriptionParams and descriptionParams[0] | length > 0 %} COMMENT '{{ descriptionParams[0] | escape }}' {%- endif %}
{%- if not loop.last -%}, {%- endif %}
{%- endfor %}
)
{%- if node.description | length > 0 %} COMMENT = '{{ node.description | escape }}' {%- endif %}
{%- elif node.materializationType | lower == 'view' %}
{# CreateSQL for View #}
{{ stage('Create ' + node.materializationType ) }}
CREATE OR REPLACE {{ node.materializationType }} {{ ref_no_link(node.location.name, node.name) }}
(
{%- for col in columns %}
{%- set descriptionParams = col.description.parameters | default([]) %}
"{{ col.name }}"
{%- if descriptionParams and descriptionParams[0] | length > 0 %} COMMENT '{{ descriptionParams[0] | escape }}' {%- endif %}
{%- if not loop.last -%}, {%- endif %}
{%- endfor %}
)
{%- if node.description | length > 0 %} COMMENT = '{{ node.description | escape }}' {%- endif %}
AS
{{ sources[0].cteString }}
SELECT {%- if config.selectDistinct %} DISTINCT {%- endif %}
{%- for col in sources[0].columns %}
{{ get_source_transform(col) }} AS "{{ col.name }}"
{%- if not loop.last -%}, {%- endif %}
{%- endfor %}
{{ sources[0].join }}
{%- endif %}
Run Template
Run Template
{#
Copyright (c) 2026 Coalesce. All rights reserved.
This script and its associated documentation are confidential and proprietary to Coalesce.
Unauthorized reproduction, distribution, or disclosure of this material is strictly prohibited.
Coalesce permits you to copy and modify this script for the purposes of using with Coalesce but
does not permit copying or modification for any other purpose.
#}
{# == Node Type Name : SQL Insert == #}
{# == Node Type Description : Creates a table with custom SQL logic == #}
{#---------------------------------------------------------------------------------------------#}
{# == To run data quality tests before data insertion == #}
{%- if node.materializationType | lower in ['table', 'transient table'] %}
{# --- Pre-SQL --- #}
{%- if config.preSQL is defined and config.preSQL.parameters is defined -%}
{%- for sql in config.preSQL.parameters -%}
{{ stage('Pre-SQL ' + loop.index|string) }}
{{ sql }}
{%- endfor %}
{%- endif %}
{# == Truncate data before data insertion == #}
{%- if config.truncateBefore %}
{{ stage('Truncate ' + node.materializationType ) }}
TRUNCATE IF EXISTS {{ ref_no_link(node.location.name, node.name) }}
{%- endif %}
{# == Insert data from sources into Work table == #}
{{ stage('Load ' + node.materializationType + ' Using Insert') }}
INSERT INTO {{ ref_no_link(node.location.name, node.name) }}
(
{%- for col in sources[0].columns %}
"{{ col.name }}"
{%- if not loop.last -%},{%- endif %}
{%- endfor %}
)
{{ sources[0].cteString }}
SELECT {%- if config.selectDistinct %} DISTINCT {%- endif %}
{%- for col in sources[0].columns %}
{{ get_source_transform(col) }} AS "{{ col.name }}"
{%- if not loop.last -%}, {%- endif %}
{%- endfor %}
{{ sources[0].join }}
{% if config.groupByAll %} GROUP BY ALL {% endif %}
{# --- Post-SQL --- #}
{%- if config.postSQL is defined and config.postSQL.parameters is defined -%}
{%- for sql in config.postSQL.parameters -%}
{{ stage('Post-SQL ' + loop.index|string) }}
{{ sql }}
{%- endfor %}
{%- endif %}
{%- else %}
{{ stage('Load Skipped for View') }}
-- The node {{node.name}} is materialized as View. Therefore, a Load operation is not supported.
SELECT 1 AS INFO_MESSAGE WHERE FALSE
{%- endif %}
{# == To run data quality tests after data insertion == #}
Coalesce does not apply annotations unless the node type declares them and your templates read the matching metadata. See SQL Annotations Reference for the annotation list and the declare-and-wire checklist.
Step 3: Add a Node and Write Your SQL
- In the Build interface, add a new Node to your graph.
- Select your V2 Node type as the Node type.
- Use the SQL editor in the center panel instead of the mapping grid. If you attach downstream from an upstream Node, the editor can pre-populate with a starter
SELECT.
V2 Nodes are stored as .sql files. The file name follows location-name.sql, where location is the storage location and name is the Node name. V1 Nodes use .yml files instead.
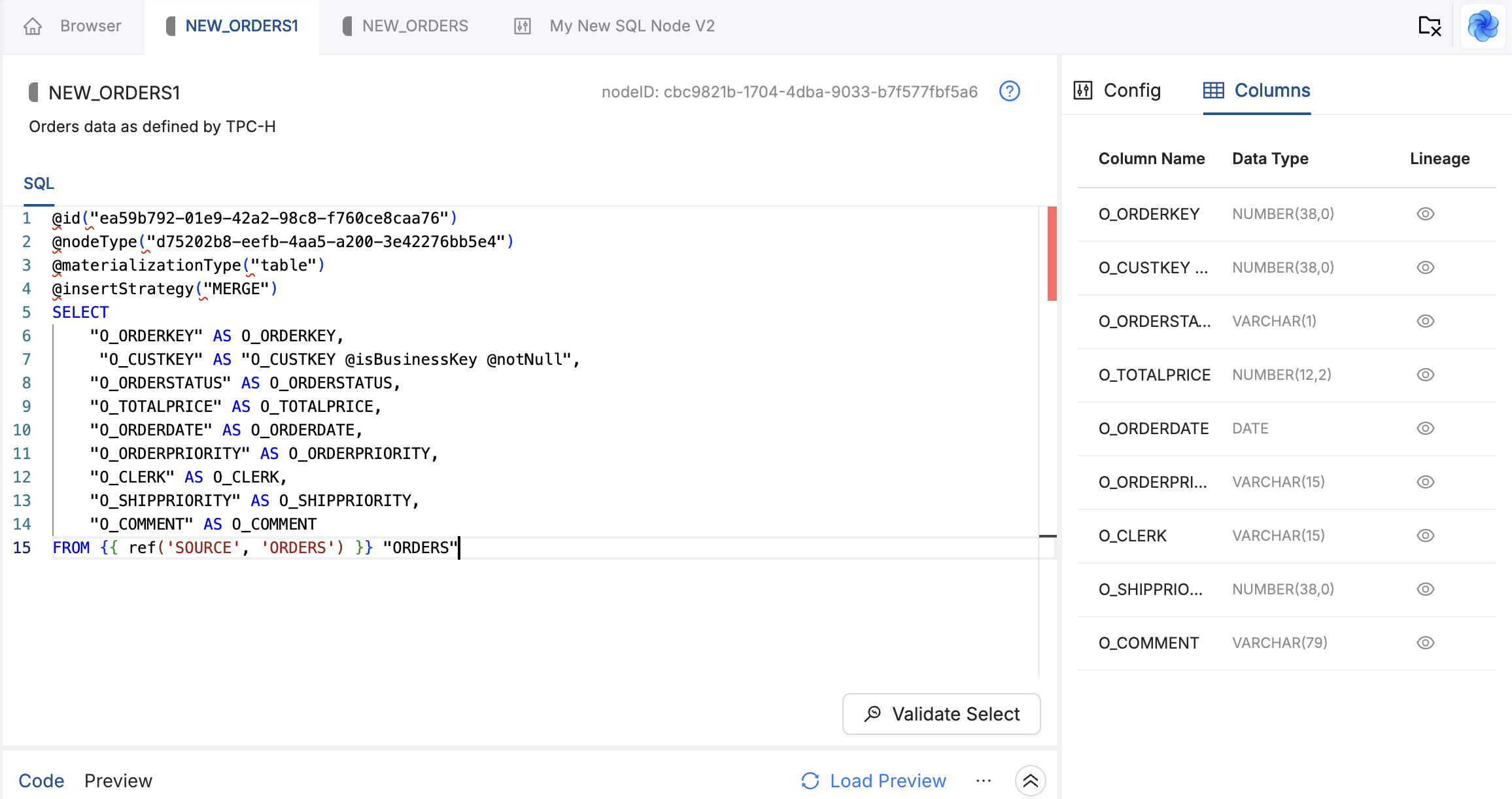
Write or paste a standard SELECT statement. Use {{ ref('LOCATION', 'NODE_NAME') }} to reference upstream Nodes so Coalesce can build the dependency graph and lineage.
SELECT
o.O_ORDERKEY AS order_key,
o.O_CUSTKEY AS customer_key,
o.O_ORDERSTATUS AS order_status,
o.O_TOTALPRICE::DECIMAL(12,2) AS order_total,
o.O_ORDERDATE AS order_date
FROM {{ ref('STAGING', 'STG_ORDERS') }} o
When you save, Coalesce parses the SELECT and the Columns tab lists each column with its inferred name and data type.
Confirm on the Columns tab that every column you expect is present with the right data types. If parsing fails for a type, add an explicit CAST in your SQL.
Coalesce adds @id and @nodeType when you create the Node. Do not edit them. See SQL Annotations Reference.
Step 4: Configure the Node with Annotations
V2 Nodes do not use the mapping grid. You configure behavior with SQL annotations in the Node file and with Options when Step 2 declared the matching config items. Your Create and Run templates must read those fields, for example config.truncateBefore or config.preSQL.parameters.
@materializationType("table")
@truncateBefore
@preSQL("ALTER SESSION SET TIMEZONE = 'UTC'")
SELECT
o.O_ORDERKEY AS order_key @isBusinessKey,
o.O_CUSTKEY AS customer_key,
o.O_ORDERSTATUS AS order_status
FROM {{ ref('STAGING', 'STG_ORDERS') }} o
Use @truncateBefore for full replace loads, not @insertStrategy("TRUNCATE"). Valid @insertStrategy values are INSERT, UNION, UNION ALL, and MERGE.
See SQL Annotations Reference for the full annotation list and template wiring.
Step 5: Validate Select, Create, and Run
- Validate Select checks the Node SQL and shows compiled SQL before you deploy.
- Create deploys the Node and runs the Create template DDL in your warehouse.
- Run executes the Run template DML and loads the table.
After running, check that lineage and data look correct:
- DAG view - upstream dependencies from your
{{ ref() }}calls appear in the graph. - Warehouse - query the target table to confirm data.
Full Example
This example uses sample data: it joins orders and line items, uses CTEs, and sets a business key with an annotation.
WITH orders_base AS (
SELECT
O_ORDERKEY AS order_key,
O_CUSTKEY AS customer_key,
O_ORDERSTATUS AS order_status,
O_TOTALPRICE AS order_total_price,
O_ORDERDATE AS order_date,
TRIM(O_ORDERPRIORITY) AS order_priority
FROM {{ ref('STAGING', 'STG_ORDERS') }} "ORDERS"
),
lineitem_base AS (
SELECT
L_ORDERKEY AS order_key,
L_LINENUMBER::NUMBER AS line_number,
L_QUANTITY AS quantity,
L_EXTENDEDPRICE AS extended_price,
L_DISCOUNT AS discount_percent,
L_EXTENDEDPRICE * (1 - L_DISCOUNT) AS discounted_price
FROM {{ ref('STAGING', 'STG_LINEITEM') }} "LINEITEM"
)
SELECT
o.order_key @isBusinessKey,
li.line_number,
o.customer_key,
o.order_date,
o.order_status,
o.order_priority,
li.quantity,
li.extended_price,
li.discount_percent,
li.discounted_price
FROM orders_base o
INNER JOIN lineitem_base li
ON o.order_key = li.order_key
After saving, the Columns tab shows 10 columns with inferred types. The DAG lists dependencies on STG_ORDERS and STG_LINEITEM. Create builds the table and Run loads it.
Best Practices
- Alias your columns. Explicit aliases give the parser the clearest signal for column names.
- Cast ambiguous types. If a column's data type shows as
UNKNOWN, add an explicit cast in your SQL:value::TIMESTAMP_NTZorCAST(value AS DECIMAL(12,2)). - Start simple. Write a basic
SELECTfirst, confirm columns parse correctly, then add CTEs, window functions, or annotations.
What's Next?
- SQL Annotations Reference for the full annotation list.
- The V2 Editor for a walkthrough of every part of the interface.
- Node Type V2 for how V2 compares to V1, platform scope, and links across the section.
- Troubleshooting and FAQ for common parse, column, and lineage issues.